Code below is connecting to my FTPserver and looks for file; these files have timestamps at start of name and added filename, like 'timestamp name.txt'. Those timestamps usually have 16 characters, look below:
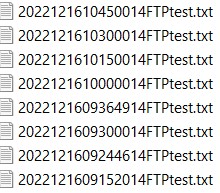
I'm trying to make this "searcher" to search files by ignoring timestamps, so it should look for 'FTPtest.txt' actually. I'm struggling with for loop usage. I did little code to test:
files = ftp.nlst()
for x in files:
print(x[16:])
This indeed lists files with cutted names but I dont know how to make use of it in my code. This code below is fully working and doing it's job, but now I need to modify it. In input user writes only short filename ('FTPtest.txt') and not full name, but it searches for exact input, ignoring timestamps. Here are just always 16 characters in timestamp, but the name can be different than FTPtest.txt. Below is my code:
from ftplib import FTP
from ftplib import FTP, error_perm
def repeat():
ftp = FTP(host="ip")
ftp.login(user='user', passwd='pass')
file_name = str(input('>>> What is name of your file? \n'))
try:
ftp.cwd('/test')
if file_name in ftp.nlst():
print(" File found! ")
else:
print("---File not found---")
except error_perm:
print("File does not exist")
ftp.quit()
while True:
repeat()
CodePudding user response:
My understanding is that you just want to see if there is a exact match by file excluding the first 16 characters so doing something like.
try:
ftp.cwd('/test')
if file_name in [f[16:] for f inftp.nlst()]:
print(" File found! ")
else:
print("---File not found---")
except error_perm:
print("File does not exist")
Should work. Note this is not the most efficient as it iterates twice over the list but it is concise.