What could be the reason that Python multiprocessing is slower that a single thread while reading binary files?
def getBinaryData(procnum, filename, pointer_from, pointer_to):
binary_values = []
start = time.time()
with open(filename, 'rb') as fileobject:
# read file byte by byte
fileobject.seek(pointer_from)
data = fileobject.read(1)
while data != b'' or pointer_position < pointer_to:
#binary_values.append(ord(data))
data = fileobject.read(1)
pointer_position = fileobject.tell()
end = time.time()
print("proc ", procnum, " finished in: ", end - start)
return binary_values
def worker(procnum, last_proc_num, file_path, bytes_chunk, return_dict):
"""worker function"""
print(str(procnum) " represent!")
if procnum == 0:
greyscale_data = getBinaryData(procnum, file_path, 0, bytes_chunk)
elif procnum == last_proc_num:
greyscale_data = getBinaryData(procnum, file_path, procnum * bytes_chunk, os.stat(file_path).st_size)
else:
greyscale_data = getBinaryData(procnum, file_path, procnum * bytes_chunk, (procnum 1) * bytes_chunk)
size = get_size(len(greyscale_data))
return_dict[procnum] = procnum
def main():
cpu_cores = 10
file_path = r"test_binary_file.exe"
file_stats = os.stat(file_path)
file_size = file_stats.st_size
manager = multiprocessing.Manager()
return_dict = manager.dict()
jobs = []
for i in range(cpu_cores):
p = multiprocessing.Process(target=worker, args=(i, cpu_cores-1, file_path, int(file_size/cpu_cores), return_dict))
jobs.append(p)
p.start()
for proc in jobs:
proc.join()
print(return_dict.values())
While single-threaded process finishes to read 10mb file in ~30seconds - the multiprocesses solution gets it done way slower.
Python log output:
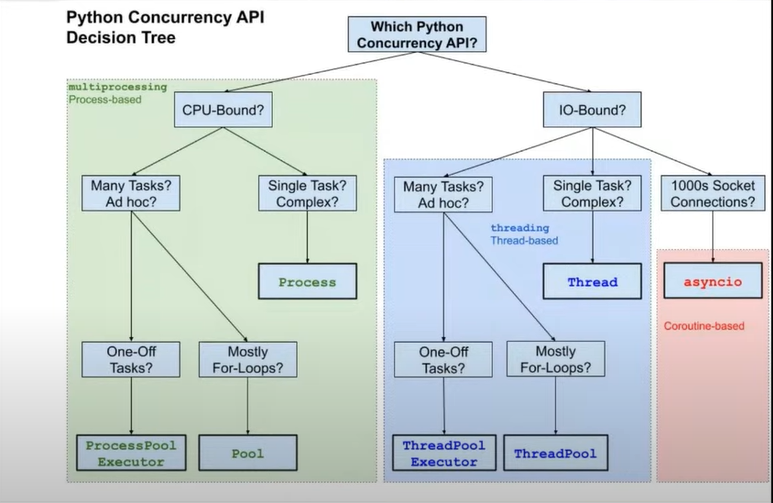 Source of picture: https://youtu.be/kRy_UwUhBpo?t=763
He told that the img is from
Source of picture: https://youtu.be/kRy_UwUhBpo?t=763
He told that the img is from fastpython.com.