Here is the site I am trying to scrap data from:
CodePudding user response:
Any website with content that is loaded after the inital page load is unavailable with BS4 with your current method. This is because the content will be loaded with an AJAX call via javascript and the requests library is unable to parse and run JS code.
To achieve this you will have to look at something like selenium which controls a browser via python or other languages... There is a seperate version of selenium for each browser i.e firefox, chrome etc.
Personally I use chrome so the drivers can be found here...
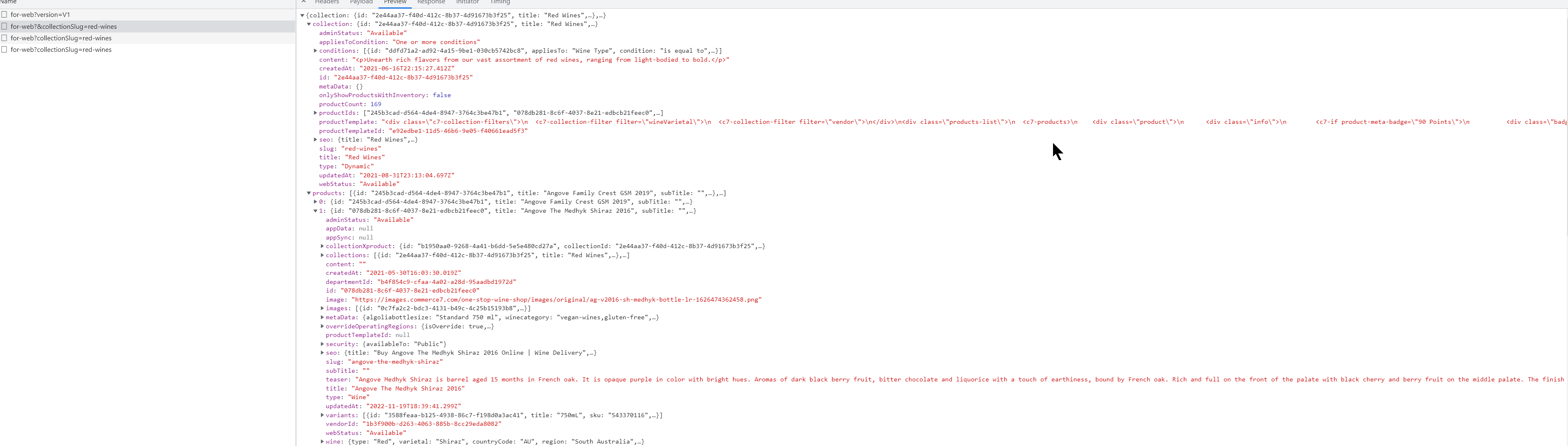
You don't need selenium or beautifulsoup at all, you can just use requests and parse the json, if you are good enough ;)