I have a .csv file as follows:
| Alphabet | Sub alphabet | Value | Strings |
|---|---|---|---|
| A | B | 1 | AA, AB |
| A | C | 1 | AA, AC |
| A | E | 2 | AB, AD |
| A | F | 3 | AA, AD, AB |
| D | B | 1 | AB, AC, AD |
| D | C | 2 | AA, AD |
| D | E | 2 | AC, AD |
| D | F | 3 | AD |
Alphabet,Sub alphabet,Value,Strings
A,B,1,"AA, AB"
A,C,1,"AA, AC"
A,E,2,"AB, AD"
A,F,3,"AA, AD, AB"
D,B,1,"AB, AC, AD"
D,C,2,"AA, AD"
D,E,2,"AC, AD"
D,F,3,AD
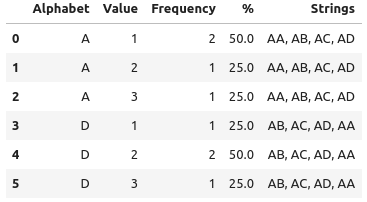
I want it to return result like this:
| Alphabet | Value | Frequency | % | Strings |
|---|---|---|---|---|
| A | 1 | 2 | 50% | AA, AB, AC, AD |
| A | 2 | 1 | 25% | AA, AB, AC, AD |
| A | 3 | 1 | 25% | AA, AB, AC, AD |
| D | 1 | 1 | 25% | AB, AC, AD, AA |
| D | 2 | 2 | 50% | AB, AC, AD, AA |
| D | 3 | 1 | 25% | AB, AC, AD, AA |
Believably expected table above is self-explanatory. The percentage refers to the corresponding row's frequency divided by total frequency. String refers to the string of the corresponding alphabet row.
My code:
import pandas as pd
df = pd.read_csv("data.csv")
df = df.groupby(["Alphabet", "Value"], as_index=False).agg(Frequency=("Value", "count"))
df["%"] = df["Frequency"] / df.groupby("Alphabet")["Frequency"].transform("sum") * 100
df.to_csv("result.csv", index=None)
Feel free to leave a comment if you need more information.
How can I make such a .csv file? I would appreciate any help. Thank you in advance!
CodePudding user response:
You can create the Strings column you'd like by splitting the string values on ', ', using explode to create separate rows for each unique value, and then selecting only the unique values with drop_duplicates:
import pandas as pd
df_inp = pd.read_csv("data.csv")
df_out = df_inp.groupby(["Alphabet", "Value"], as_index=False).agg(Frequency=("Value", "count"))
df_out["%"] = df_out["Frequency"] / df_out.groupby("Alphabet")["Frequency"].transform("sum") * 100
df_str_vals = df_inp[['Alphabet', 'Strings']].assign(str_vals=lambda x: x['Strings'].str.split(', ')).explode('str_vals').drop(columns='Strings').drop_duplicates()
Then you can use groupby to join the unique string values for each Alphabet value back together:
df_str_vals = df_str_vals.groupby(["Alphabet"], as_index=False)['str_vals'].apply(', '.join).rename(columns={'str_vals': 'Strings'})
leading to this result:
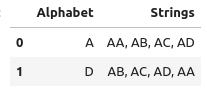
Finally, merge the df_str_vals dataframe back with your earlier result to obtain the Strings column for the output dataframe to write to the csv file:
df_out = df_out.merge(df_str_vals, on='Alphabet')
df_out.to_csv("result.csv", index=None)