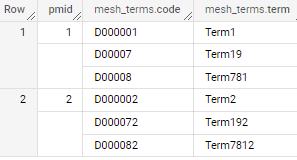
I've got a column that has entries (variable numbers of 2-tuples) like this:
D000001:Term1;D00007:Term19;D00008:Term781 (mesh_terms column below) and I'd like to split those so that I end up with an ARRAY<STRUCT<code STRING, term STRING>> for each row.
The query below works as needed, but I'm curious if anyone has suggestions on improvements in terms of readability, performance (on Bigquery, so not too big a problem), or best practices.
with t1 as (
SELECT
pmid,
split(mesh_terms, ';') as l1
FROM `omicidx_etl.pm1`
),
t2 as (
select
t1.pmid,
x
from t1,
unnest(t1.l1) as x
),
t3 as (
select
pmid,
split(x, ':') as y
from t2
)
select
pmid,
array_agg(STRUCT(t3.y[offset(0)] as code, t3.y[offset(1)] as term)) as mesh_terms
from
t3
group by pmid
CodePudding user response:
Use below
select pmid,
array(
select as struct split(kv, ':')[offset(0)] code, split(kv, ':')[safe_offset(1)] term
from unnest(regexp_extract_all(mesh_terms, r'[^:;] :[^:;] ')) kv
) mesh_terms
from your_table
if applied to sample data like in your question - output is