This writes all records, including null PbRatios. I would like to write the last non-null record only. When I add df[df.asOfDate == df.asOfDate.max()].to_csv, it gets the last record, which is always null.
import pandas as pd
from yahooquery import Ticker
symbols = ['AAPL','GOOG','MSFT','NVDA']
header = ["asOfDate","PbRatio"]
for tick in symbols:
faang = Ticker(tick)
faang.valuation_measures
df = faang.valuation_measures
try:
for column_name in header :
if column_name not in df.columns:
df.loc[:,column_name ] = None
df.to_csv('output.csv', mode='a', index=True, header=False, columns=header)
except AttributeError:
continue
Current output:
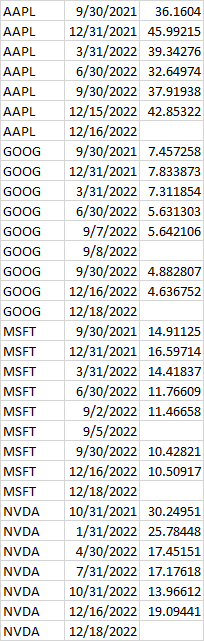
Desired output:
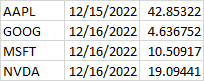
CodePudding user response:
This should work. Just filter for the not Nan values in the df and filter for the max asOfDate.
for tick in symbols:
faang = Ticker(tick)
faang.valuation_measures
df = faang.valuation_measures
try:
for column_name in header :
if column_name not in df.columns:
df.loc[:,column_name ] = None
except AttributeError:
continue
# filter for notna
df = df[df['PbRatio'].notna()]
# filter for max date
df = df[df['asOfDate'] == df['asOfDate'].max()]
df.to_csv('output.csv', mode='a', index=True, header=False, columns=header)
CodePudding user response:
Here I created a dummy data to work with, would have been nice if you provided data.
df = pd.DataFrame([['A',12,123],['A',13,125],['A',2,None],['B',16,133],
['B',16,None],['B',14,139]], columns=['Name','id','score'])
Name id score
0 A 12 123.0
1 A 13 125.0
2 A 2 NaN
3 B 16 133.0
4 B 16 NaN
5 B 14 139.0
then you drop the rows with missing values
df = df.dropna(how = 'any')
this looks like this:
Name id score
0 A 12 123.0
1 A 13 125.0
3 B 16 133.0
5 B 14 139.0
I get the set of unique names, this is whatever 'AAPL'/'NVDA' column you have
names = set(df['Name'])
create a new dataframe where I grab only the last row for each unique name, in my example that would be 'A' and 'B'. in yours that should be 'AAPL'/'NVDA'.
new_df = pd.DataFrame(columns=df.columns)
for n in names:
new_df.loc[new_df.shape[0]] = df.loc[df.query(f"Name== '{n}'").index[-1]]
and this should look like
new_df
>>>
Name id score
0 B 14 139.0
1 A 13 125.0