Here is my code:
from multiprocessing.dummy import Pool
def process_board(elems):
# do something
for _ in range(1000):
with Pool(cpu_count()) as p:
_ = p.map(process_board, enumerate(some_array))
and this is the activity monitor of my mac while the code is running:
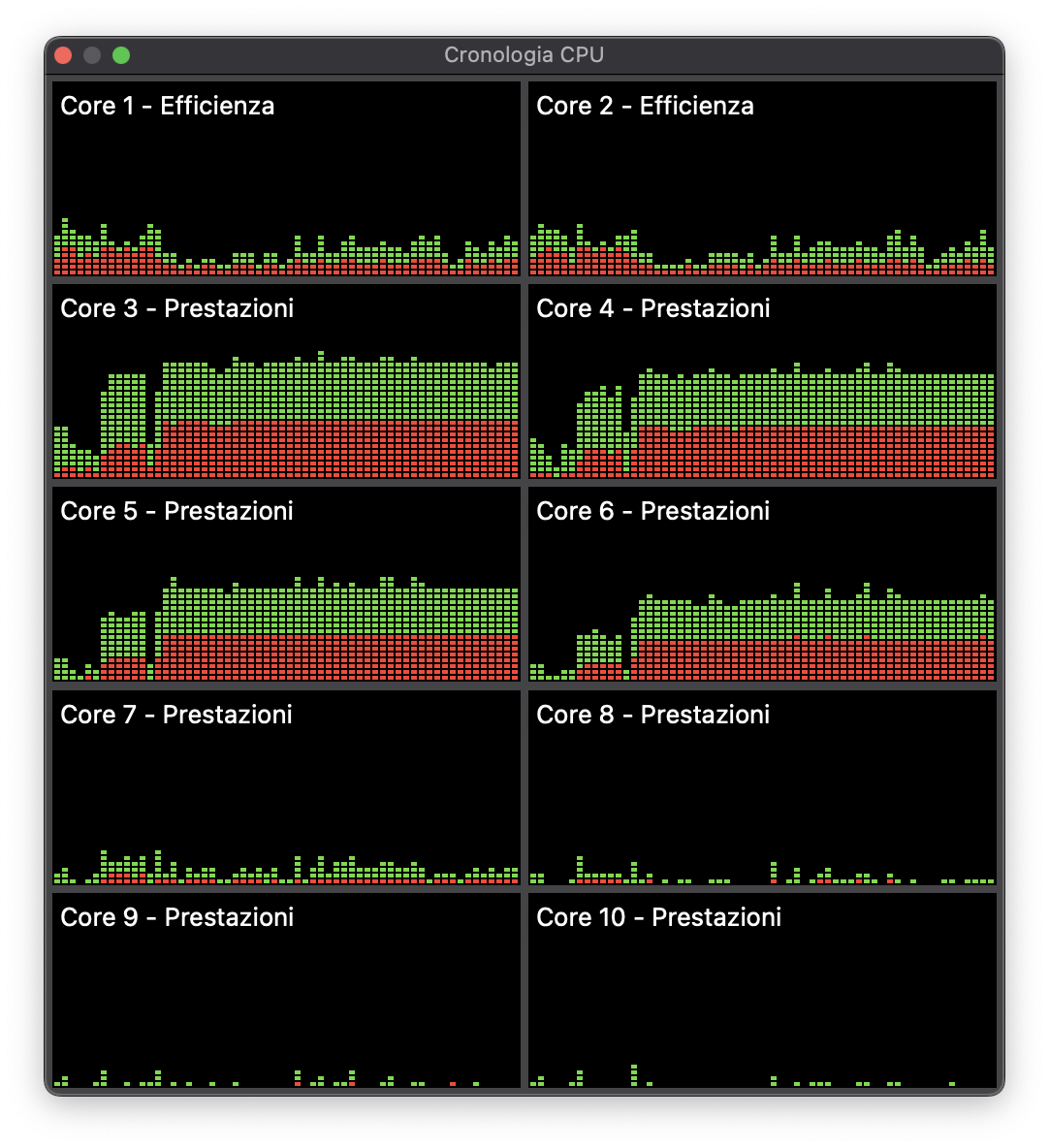
I can ensure that len(some_array) > 1000, so there is for sure more work that can be distributed, but seems not the case... what am I missing?
Update:
I tried chunking them, to see if there is any difference:
# elements per chunk -> time taken
# 100 -> 31.9 sec
# 50 -> 31.8 sec
# 20 -> 31.6 sec
# 10 -> 32 sec
# 5 -> 32 sec
consider that I have around 1000 elements, so 100 elements per chunk means 10 chunks, and this is my CPU loads during the tests:
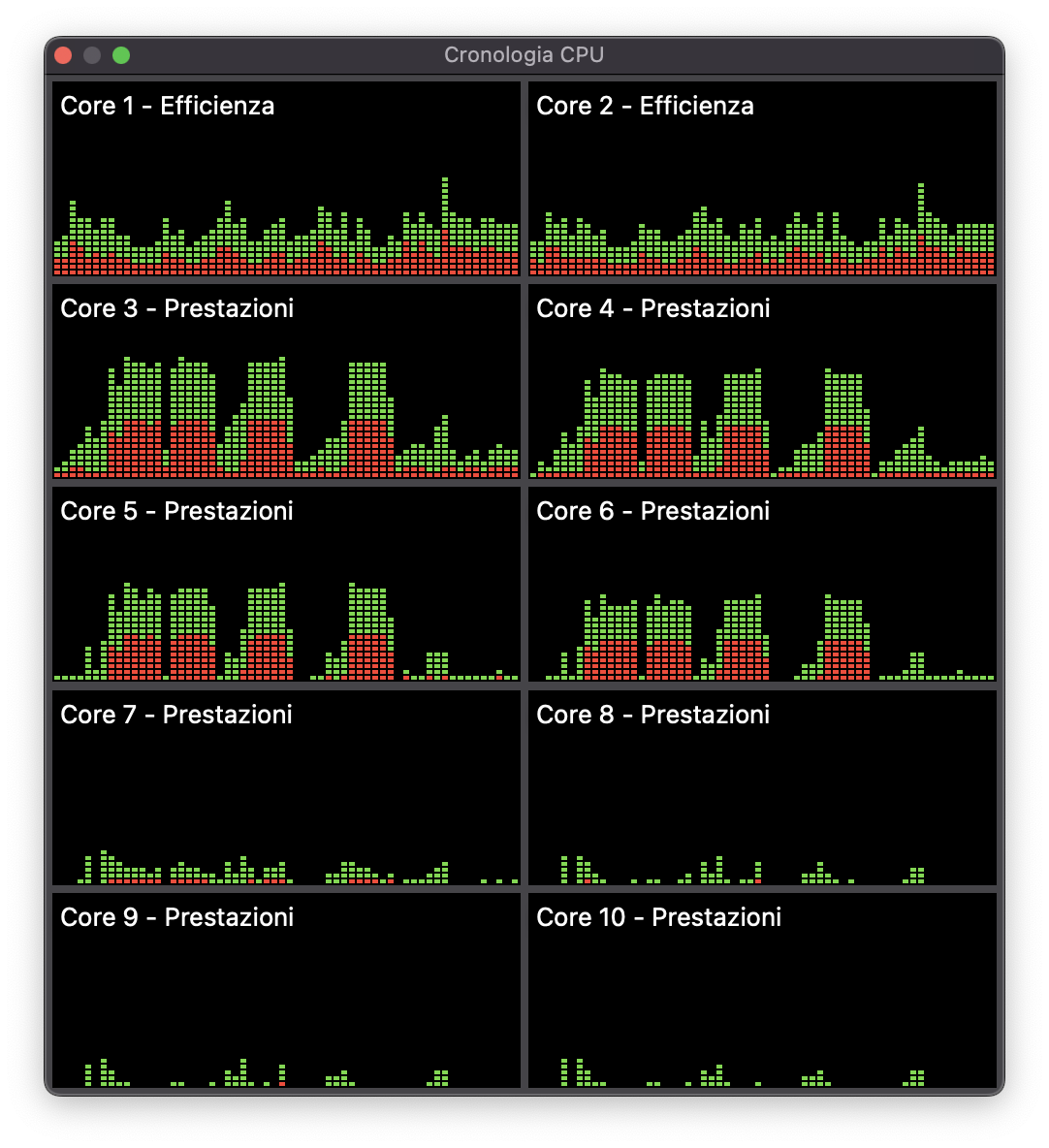
As you can see, changing the number of chunks does not help to use the last 4 CPUS...
CodePudding user response:
You were using multiprocessing.dummy.Pool which is a thread pool that looks like a multiprocessing pool. This is good for I/O tasks that release the GIL but has no advantage with CPU bound tasks. To note, the python Global Interpreter Lock (GIL) ensures that only a single thread can execute byte code at a time.
Whether multiprocessing speeds things up depends on the cost of sending data to and from the worker subprocesses verses the amount of work done on the data.