I'm stuck with this issue:
I want to replace each row in one column in csv with id.
I have vehicle names and id's in the database:
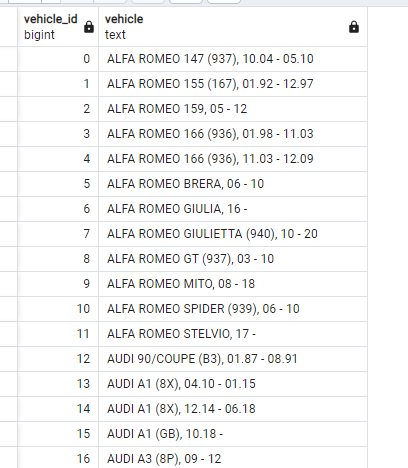
In csv file this column look like this:
I was thinking to use pandas, to make a replacement:
df = pd.read_csv(file).replace('ALFA ROMEO 147 (937), 10.04 - 05.10', '0')
But it is the wrong way to write replace 2000 times.
So, how can I use names from db and replace them with the correct id?
CodePudding user response:
A possible solution is to merge the second dataset with the first one: After reading the two datasets (df1, the one from the csv file, and df2, the one with vehicle_id):
df1.merge(df2, how='left', on='vehicle')
So that the final output will be a dataset with columns:
id, vehicle, vehicle_id
Imagine df1 as:

and df2 as:
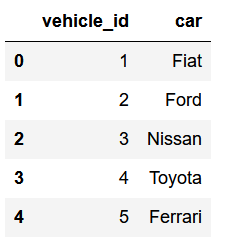
the result will be:

Here you can find the documentation: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html