I have a historical table that keeps track of the status of a task over time. The table looks similar to the below, where the 'ID' is unique to the task, 'Date' changes whenever an action is taken on the task, 'Factor1, Factor2, etc' are columns that contain details of the underlying task.
I want to flag on an 'ID' level, what 'Factor' columns are changing over time. Once I identify which 'Factor' columns are changing, I am planning on doing analysis to see which 'Factor' columns are changing the most, the least, etc.
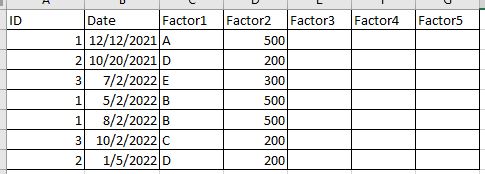
I am looking to:
- Sort by 'Date' ascending
- Groupby 'ID'
- Loop through each column that has 'Factor' in the column name and for each column, identify if the 'Factor' data changed by looping through each row for each ID
- Create a new column for each 'Factor' column to flag if the underlying factor row changed overtime for that specific ID
Python code for sample data:
import pandas as pd
data = [[1,'12/12/2021','A',500],[2,'10/20/2021','D',200],[3,'7/2/2022','E',300],
[1,'5/2/2022','B',500],[1,'8/2/2022','B',500],[3,'10/2/2022','C',200],
[2,'1/5/2022','D',200]]
df = pd.DataFrame(data, columns=['ID', 'Date','Factor1','Factor2'])
My desired output is this: 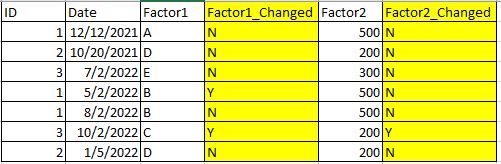
CodePudding user response:
import pandas as pd
data = [[1, '12/12/2021', 'A', 500], [2, '10/20/2021', 'D', 200], [3, '7/2/2022', 'E', 300],
[1, '5/2/2022', 'B', 500], [1, '8/2/2022', 'B', 500], [3, '10/2/2022', 'C', 200],
[2, '1/5/2022', 'D', 200]]
df = pd.DataFrame(data, columns=['ID', 'Date', 'Factor1', 'Factor2'])
# get the 'Factor' columns
factor_columns = [col for col in df.columns if col.startswith('Factor')]
# returns Y if previous val has changed else N
def check_factor(x, col, df1):
# assigning previous value if exist or target factor value if NaN
val = df1[df1.ID == x.ID].shift(1)[col].fillna(x[col]).loc[x.name]
return 'N' if val == x[col] else 'Y'
# creating new columns list to reorder columns
columns = ['ID', 'Date']
for col in factor_columns:
columns = [col, f'{col}_Changed']
# applying check_factor to new column
df[f'{col}_Changed'] = df.apply(check_factor, args=(col, df.copy()), axis=1)
df = df[columns]
print(df)
OUTPUT:
ID Date Factor1 Factor1_Changed Factor2 Factor2_Changed
0 1 12/12/2021 A N 500 N
1 2 10/20/2021 D N 200 N
2 3 7/2/2022 E N 300 N
3 1 5/2/2022 B Y 500 N
4 1 8/2/2022 B N 500 N
5 3 10/2/2022 C Y 200 Y
6 2 1/5/2022 D N 200 N