I'm trying to join a main dataframe with a nested dict extracted in another dataframe
main dataframe

extracted dict
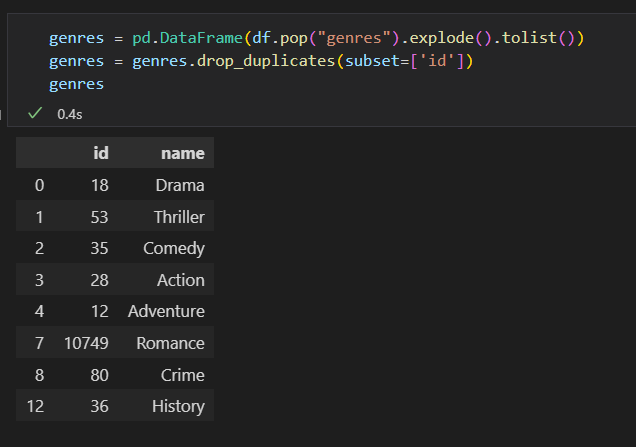
expected outcome
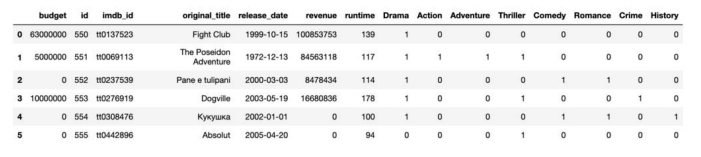
This is what i have tried
x = pd.concat([df, pd.get_dummies(genres['name'])], axis=1)
x
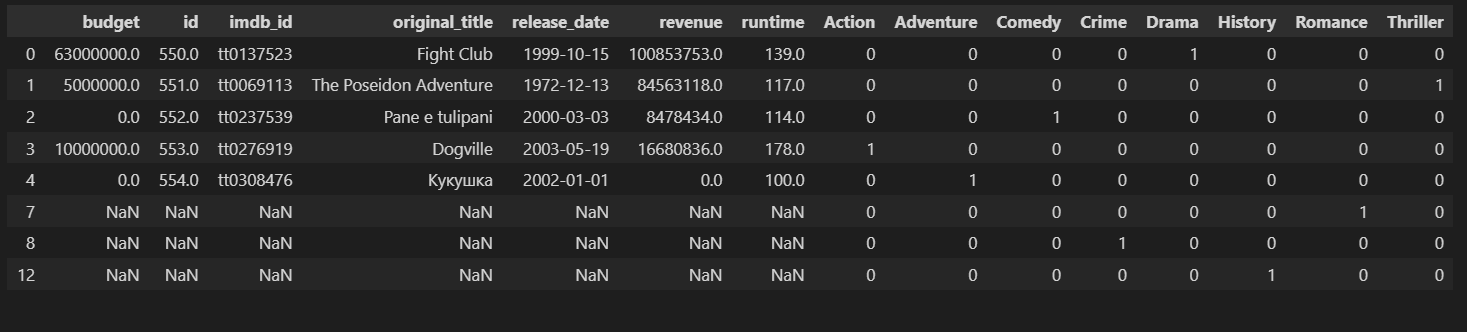
CodePudding user response:
If I understand this right, you have only one dataframe, df, and you have just exploded the one column including the genre and try to merge it back to the original dataframe. In that case, you do not need to do it this way. Just use this function. It'll fatten the entire dataframe.
def flatten_nested_json_df(df):
df = df.reset_index()
s = (df.applymap(type) == list).all()
list_columns = s[s].index.tolist()
s = (df.applymap(type) == dict).all()
dict_columns = s[s].index.tolist()
while len(list_columns) > 0 or len(dict_columns) > 0:
new_columns = []
for col in dict_columns:
exploded = pd.json_normalize(df[col]).add_prefix(f'{col}.')
exploded.index = df.index
df = pd.concat([df, exploded], axis=1).drop(columns=[col])
new_columns.extend(exploded.columns) # inplace
for col in list_columns:
# print(f"exploding: {col}")
df = df.drop(columns=[col]).join(df[col].explode().to_frame())
new_columns.append(col)
s = (df[new_columns].applymap(type) == list).all()
list_columns = s[s].index.tolist()
s = (df[new_columns].applymap(type) == dict).all()
dict_columns = s[s].index.tolist()
return df
Do, then
flatten_nested_json_df(df)
and it should given you what you expected.
If it is so that you have 2 dataframes, df1 (which you want to flatten) and df2 to merge to, do the same thing with df1 and then:
df_final = df1.merge(df2, on = ['id'])
CodePudding user response:
IIUC, you can use:
hot = pd.get_dummies(df.pop('genre').explode().str['name']).groupby(level=0).max()
df = pd.concat([df, hot], axis=1)
print(df)
# Output
id original_title Action Comedy Drama
0 123 Hello 1 0 1
1 456 World 0 1 0
Input data:
data = {'genre': [[{'id': 18, 'name': 'Drama'}, {'id': 28, 'name': 'Action'}],
[{'id': 35, 'name': 'Comedy'}]],
'id': [123, 456], 'original_title': ['Hello', 'World']}
df = pd.DataFrame(data)
print(df)
# Output
genre id original_title
0 [{'id': 18, 'name': 'Drama'}, {'id': 28, 'name... 123 Hello
1 [{'id': 35, 'name': 'Comedy'}] 456 World