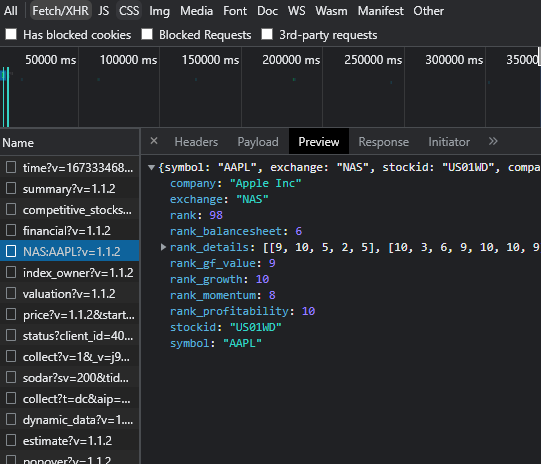
Here's the website in question:
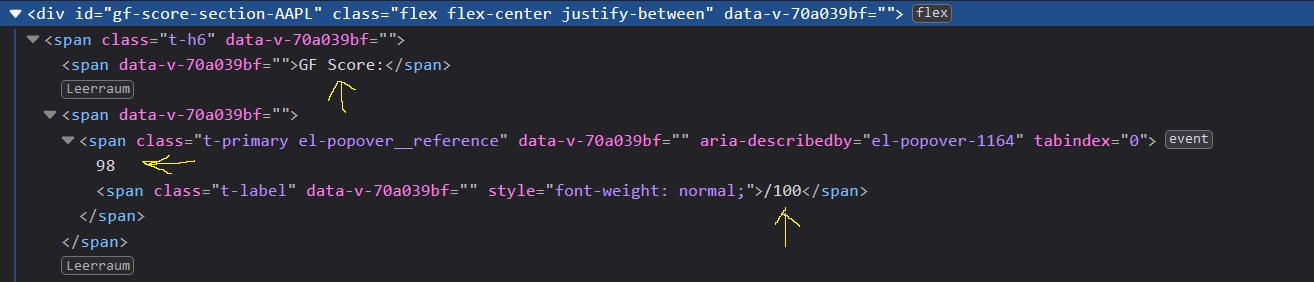
I need to extract the strings 'GF Score' and '98/100'.
Firefox Inspector gives me span.t-h6 > span:nth-child(1) as a CSS Selector but I just can't seem to fetch neither the numbers nor the descriptor.
Here's the code that I've used so far to extract the "GF Score" part:
import requests
import bs4 as BeautifulSoup
from lxml import html
req = requests.get('https://www.gurufocus.com/stock/AAPL')
soup = BeautifulSoup(req.content, 'html.parser')
score_soup = soup.select('#gf-score-section-003550 > span > span:nth-child(1)')
score_soup_2 = soup.select('span.t-h6 > span')
print(score_soup)
print(score_soup_2)
tree = html.fromstring(req.content)
score_lxml = tree.xpath ('//*[@id="gf-score-section-003550"]/span/span[1]')
print(score_lxml)
As a result, I'm getting three empty brackets.
The xpath was taken directly out of chrome via the copy function and the nth-child expression in the BS4 part also.
Any suggestions as to what might be at fault here?
CodePudding user response:
Unfortunately get the page using Requests lib impossible, as well as access to the api to which the signature is needed. There is 2 option:
Use