I am writing to ask for a hand in downloading an HTML page that contains various shadow-roots
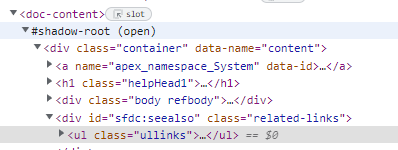
When I try to download this page (https://developer.salesforce.com/docs/atlas.en-us.apexref.meta/apexref/apex_namespace_System.htm) with python, the result is the base HTML without all the node content in the shadow-root.
This is my test code:
from bs4 import BeautifulSoup as bs
import urllib.request
url_apex_namespace_System = 'https://developer.salesforce.com/docs/atlas.en-us.apexref.meta/apexref/apex_namespace_System.htm'
print(f"Retrive Html from {url_apex_namespace_System}")
fid = urllib.request.urlopen(url_apex_namespace_System)
webpage = fid.read().decode('utf-8')
bs_content = bs(webpage, "html")
print(webpage)
# If in the future id change, change it here
classLi = bs_content.find_all("div", {"id": "sfdc:seealso"},recursive=True)
And the classLi variable result is equal to NoneType because the element is inside the shadow-root.
Thanks in advance
My expectation is that: classLi have to contain the search div inside the shadow-root.
CodePudding user response:
Solution
After much searching and trying I was able to find a solution that works for my page and explained it. It is not yet a general and systematic solution, if anyone has other ideas to improve it do not hesitate, in any case here is the commented script that works in a systematic way (as of today 11/01/2023).
Request Chrome and this package:
pip install selenium chromedriver_binary
seleniumis an open-source library that permits it to operate inside a web browser instance, typically used for debugging and testing code. Here is used to extract information from the browser environment.chromedriver_binaryis a plugin to command the chromium browser.
To understand the code remember this structure for shadow-root DOM:
(Manual ref: https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_shadow_DOM)
The code:
from selenium import webdriver
from selenium.webdriver.common.by import By
url = 'https://developer.salesforce.com/docs/atlas.en-us.apexref.meta/apexref/apex_namespace_System.htm'
timeout = 10
driver = webdriver.Chrome() # Open Chromium instance where the code and shadow-root can be processed
driver.implicitly_wait(timeout) # Set timeout before run command, it give the time at the DOM to self create
driver.get(url) # Open Chrome page at request url
# The following block of code was written specifically for this case, unfortunately for now it is not a complete and automatic solution.
# With the CSS_SELECTOR (using ID and tag_name) the code travel through the DOM.
shadow_host_1 = driver.find_element(By.CSS_SELECTOR, '#maincontent > doc-xml-content')
shadow_root_1 = shadow_host_1.shadow_root
shadow_host_2 = shadow_root_1.find_element(By.CSS_SELECTOR, 'doc-content')
shadow_root_2 = shadow_host_2.shadow_root
# <-- In the Salesforce Reference manual, all page after this point has all the shadow content in the main div loaded (True today @ 11/01/23)
# Finally reach the target Shadow DOM tree, simply search the correct tag and export the HTML data
element = shadow_root_2.find_element(By.CSS_SELECTOR, 'div.related-links')
elementHTML = element.get_attribute("outerHTML") # get_attribute("outerHTML") return html Tag Content
print(elementHTML)
driver.quit()
This solution isn't global, need to process all shadow-root, and for that reason is important to know the final structure. Is easy to generate this code with the developer console in chrome, but I think should be a solution more elegant... Feel free to develop a solution more elegant and powerful!
IMPORTANT: Because the shadow-root is different DOM-TREE and the browser merge it with the dad in the rendering phase without 'driver.implicitly_wait(timeout)' the result isn't deterministic because Total DOM could not load
and the 'find_element' fails to find part reach after multiple loads."