I have a dateframe that looks like :
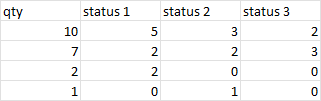
df = pd.DataFrame({'qty': [10,7,2,1],
'status 1': [5,2,2,0],
'status 2': [3,2,0,1],
'status 3': [2,3,0,0]
})
Each row has a qty of items. These items have one status (1,2 or 3).
So qty = sum of values of status 1,2,3.
I would like to :
1/ duplicate each row by the "qty" column
2/ Then edit 3 status (or update a new column), to get just 1 status.
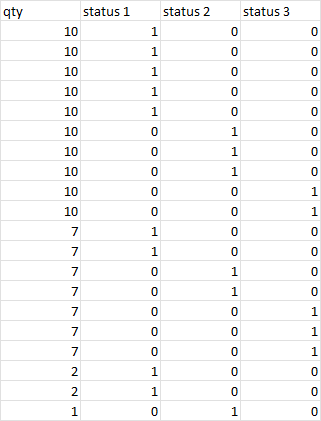
The output should looks like :
My (incomplete) solution so far :
I found a way to duplicate the rows using this :
df2= df2.loc[df2.index.repeat(df2['qty'])].reset_index(drop=True)
But I can't find a way to fill the status. Do I need to use a for loop approach to fill the status ? Should I do this transform in 1 or 2 steps ?
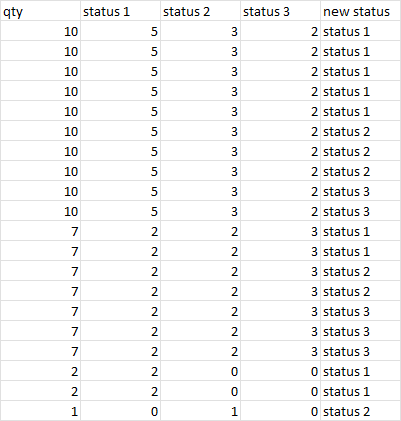
Something like : for each initial row, the n first rows take the first status, where n is the value of status 2....
The output could maybe looks like :
Thank you in advance, Best
CodePudding user response:
Here is a way:
(df[['qty']].join(df.iloc[:,1:].stack()
.map(lambda x: list(range(1,x 1)))
.explode()
.dropna()
.fillna(0)
.to_frame()
.assign(cc = lambda x: x.groupby(level=0).cumcount())
.set_index('cc',append=True)[0]
.unstack(level=1)
.droplevel(1)
.fillna(0)
.astype(bool)
.astype(int))
.reset_index(drop=True))
Output:
qty status 1 status 2 status 3
0 10 1 0 0
1 10 1 0 0
2 10 1 0 0
3 10 1 0 0
4 10 1 0 0
5 10 0 1 0
6 10 0 1 0
7 10 0 1 0
8 10 0 0 1
9 10 0 0 1
10 7 1 0 0
11 7 1 0 0
12 7 0 1 0
13 7 0 1 0
14 7 0 0 1
15 7 0 0 1
16 7 0 0 1
17 2 1 0 0
18 2 1 0 0
19 1 0 1 0
CodePudding user response:
hardcoded, but a more human readable approach:
import pandas as pd
df = pd.DataFrame({'qty': [10,7,2,1],
'status 1': [5,2,2,0],
'status 2': [3,2,0,1],
'status 3': [2,3,0,0]
})
df2 = pd.DataFrame(data=None, columns=df.columns)
cnt = 0
for idx, row in df.iterrows():
s_one = row['status 1']
s_two = row['status 2']
s_three = row['status 3']
while s_one > 0:
df2.loc[cnt] = [row['qty'],1,0,0]
s_one-=1
cnt =1
while s_two > 0:
df2.loc[cnt] = [row['qty'],0,1,0]
s_two-=1
cnt =1
while s_three > 0:
df2.loc[cnt] = [row['qty'],0,0,1]
s_three-=1
cnt =1
print(df2)
same output.
CodePudding user response:
You can using this.
Instead of repeating on df['qty'], repeat on the status themselves, the concatenate the results and sort:
df = pd.DataFrame({'qty': [10,7,2,1],
'status 1': [5,2,2,0],
'status 2': [3,2,0,1],
'status 3': [2,3,0,0]
})
cols = ['status 1', 'status 2', 'status 3']
df_out = pd.concat([df.loc[df.index.repeat(df[col]), [col] ['qty']].reset_index()
for col in cols], ignore_index=True).sort_values(['index'] cols)
df_out[cols] = df_out[cols].notna().astype(int)
df_out[['qty'] cols]
Output:
qty status 1 status 2 status 3
0 10 1 0 0
1 10 1 0 0
2 10 1 0 0
3 10 1 0 0
4 10 1 0 0
9 10 0 1 0
10 10 0 1 0
11 10 0 1 0
15 10 0 0 1
16 10 0 0 1
5 7 1 0 0
6 7 1 0 0
12 7 0 1 0
13 7 0 1 0
17 7 0 0 1
18 7 0 0 1
19 7 0 0 1
7 2 1 0 0
8 2 1 0 0
14 1 0 1 0
CodePudding user response:
Here is a possible solution:
import numpy as np
import pandas as pd
E = pd.DataFrame(np.eye(df.shape[1] - 1, dtype=int))
result = pd.DataFrame(
df['qty'].reindex(df.index.repeat(df['qty'])).reset_index(drop=True),
)
result[df.columns[1:]] = pd.concat(
[E.reindex(E.index.repeat(df.iloc[i, 1:]))
for i in range(len(df))],
).reset_index(
drop=True,
)
Here is the result:
>>> result
qty status 1 status 2 status 3
0 10 1 0 0
1 10 1 0 0
2 10 1 0 0
3 10 1 0 0
4 10 1 0 0
5 10 0 1 0
6 10 0 1 0
7 10 0 1 0
8 10 0 0 1
9 10 0 0 1
10 7 1 0 0
11 7 1 0 0
12 7 0 1 0
13 7 0 1 0
14 7 0 0 1
15 7 0 0 1
16 7 0 0 1
17 2 1 0 0
18 2 1 0 0
19 1 0 1 0