I have these dataFrames:
df_1 = pd.DataFrame({
'Color': ['Azul','Verde'],
})
df_2 = pd.DataFrame({
'Palabra': ['a','b','c']
})
df_3 =df_1.merge(df_2,how='cross')
df_3['Valor'] = 0
df_4 = pd.DataFrame({
'Color': ['Azul','Azul'],
'Palabra': ['a','c'],
'Valor': [1,2]
})
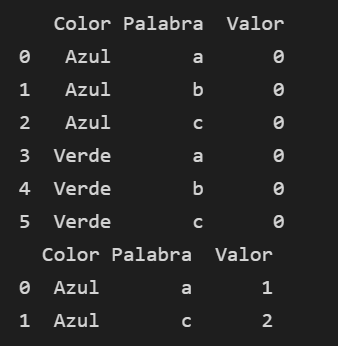
I want that df_3 has the values of the column 'Valor' if they exist in df_4. I'm trying the following merge:
df_5 = pd.merge(df_3,df_4,how='left',left_on=['Color','Palabra'],
right_on=['Color','Palabra'])
But it gives me the following DF:
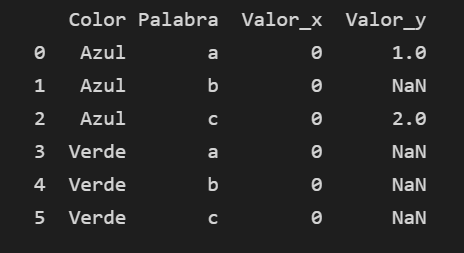
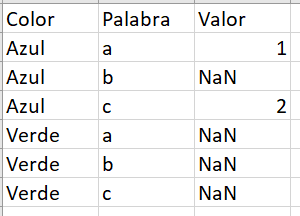
I want that the column 'Valor' looks like the column 'Valor_y' but I can´t seem to make it work. I would appreciate a help to make it look like this:
CodePudding user response:
Right idea with the merge, just don't merge with the 'Valor' column on df_3.
df_3[['Color', 'Palabra']].merge(df_4,
how = 'left',
on = ['Color', 'Palabra']).fillna(0)
You can drop the .fillna(0) if you want the missing values to be NaN instead.
Alternatively, if you have a ton of columns and want to avoid using merge, which is kind of slow. You can convert df_4 to a dictionary and then map the it.
valor_dict = df_4.set_index(['Color', 'Palabra'])['Valor'].to_dict()
df_3['Valor'] = [valor_dict.get((col,pal), 0)
for col, pal
in zip(df_3.Color, df_3.Palabra)]
CodePudding user response:
You can use iloc to use only the first 2 columns of df_3 in the merge:
df_5 = pd.merge(df_3.iloc[:, :2],df_4,how='left',left_on=['Color','Palabra'],
right_on=['Color','Palabra'])
Output:
Color Palabra Valor
0 Azul a 1.0
1 Azul b NaN
2 Azul c 2.0
3 Verde a NaN
4 Verde b NaN
5 Verde c NaN
CodePudding user response:
Actually you don't need to initiate a column Valor in df_3.
So remove the line df_3['Valor'] = 0 and then do a outer merge:
df_4.merge(df_3, how='outer')
or if you don't want to remove the line that initiates the column Valor you can just do
df_4.merge(df_3.drop(columns='Valor'), how='outer')
Color Palabra Valor
0 Azul a 1.0
1 Azul c 2.0
2 Azul b NaN
3 Verde a NaN
4 Verde b NaN
5 Verde c NaN