I have a dataset like this:
- id : E.g. 111, 111, 111, 112, 112, 113, 113
- Year: E.g. 2010, 2011, 2012, 2010, 2011,2010, 2015
- Sex: E.g. M, M, F, F, F, M, M
In this dataset, ID = 111 had a sex change (switch from M to F - or from F to M)
With postgre sql, I try to find out:
- A: How many ids stay as man (and which ids)
- B: How many ids stay as woman (and which ids)
- C: How many ids go from man to woman (and which ids)
- D: How many ids go from woman to man (and which ids)
I try like this:
# problem A
SELECT COUNT(DISTINCT ID) FROM table WHERE ID NOT IN (SELECT ID FROM table WHERE SEX = 'M');
SELECT DISTINCT ID FROM table WHERE ID NOT IN (SELECT ID FROM table WHERE SEX = 'M');
# problem B
SELECT COUNT(DISTINCT ID) FROM table WHERE ID NOT IN (SELECT ID FROM table WHERE SEX = 'F');
SELECT DISTINCT ID FROM table WHERE ID NOT IN (SELECT ID FROM table WHERE SEX = 'F');
# all sex change
SELECT COUNT(DISTINCT ID) FROM table WHERE ID IN (SELECT ID FROM table WHERE SEX = 'M') AND ID IN (SELECT ID FROM table WHERE SEX = 'F');
SELECT DISTINCT ID FROM table WHERE ID IN (SELECT ID FROM table WHERE SEX = 'M') AND ID IN (SELECT ID FROM table WHERE SEX = 'F');
Is it correct? Or is window-lag function needed?
CodePudding user response:
You can try this, to calculate in advance some metrics:
SELECT *
,MAX(CASE WHEN sex = 'M' THEN 1 ELSE 0 END) OVER (PARTITION BY ID) AS has_M
,MAX(CASE WHEN sex = 'F' THEN 1 ELSE 0 END) OVER (PARTITION BY ID) AS has_F
,DENSE_RANK() OVER (PARTITION BY id ORDER BY id, year) AS initial_sex
FROM mytable;
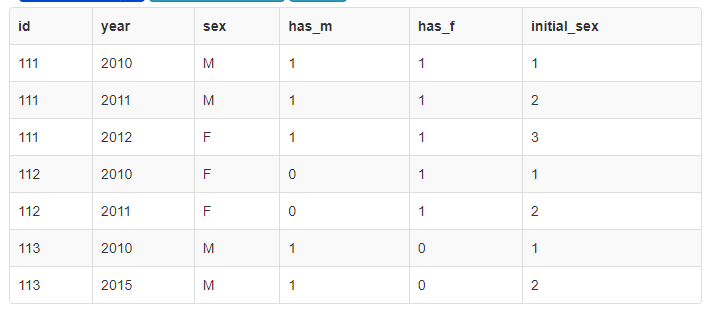
and then solve your issues:
SELECT SUM(CASE WHEN initial_sex = 1 AND SEX = 'M' THEN 1 ELSE 0 END)
,string_agg(CASE WHEN initial_sex = 1 AND SEX = 'M' THEN CAST(id AS VARCHAR(12)) END, ', ')
,SUM(CASE WHEN initial_sex = 1 AND SEX = 'F' THEN 1 ELSE 0 END)
,string_agg(CASE WHEN initial_sex = 1 AND SEX = 'F' THEN CAST(id AS VARCHAR(12)) END, ', ')
,SUM(CASE WHEN (initial_sex = 1 AND SEX = 'F' AND has_m = 1) OR (initial_sex = 1 AND SEX = 'M' AND has_F = 1) THEN 1 ELSE 0 END)
,string_agg(CASE WHEN (initial_sex = 1 AND SEX = 'F' AND has_m = 1) OR (initial_sex = 1 AND SEX = 'M' AND has_F = 1) THEN CAST(id AS VARCHAR(12)) END, ', ')
FROM
(
SELECT *
,MAX(CASE WHEN sex = 'M' THEN 1 ELSE 0 END) OVER (PARTITION BY ID) AS has_M
,MAX(CASE WHEN sex = 'F' THEN 1 ELSE 0 END) OVER (PARTITION BY ID) AS has_F
,DENSE_RANK() OVER (PARTITION BY id ORDER BY id, year) AS initial_sex
FROM mytable
) DS;

Here is the full working example.
CodePudding user response:
Assuming column SEX will only have either 'F' or 'M' as value, problem A can be solved
problem A
SELECT COUNT(DISTINCT ID) FROM table WHERE SEX != 'F';
SELECT DISTINCT ID FROM table WHERE SEX != 'F';