Consider the DataFrame df
df = pd.DataFrame({'Name': ['Tesla','Tesla','Tesla','Toyota','Ford','Ford','Ford','BMW','BMW','BMW','Mercedes','Mercedes','Mercedes'],
'Type': ['Model X','Model X','Model X','Corolla','Bronco','Bronco','Mustang','3 Series','3 Series','7 Series','C-Class','C-Class','S-Class'],
'Year': [2015, 2015, 2015, 2017, 2018, 2018, 2020, 2015, 2015, 2017, 2018, 2018, 2020],
'Price': [85000, 90000, 95000, 20000, 35000, 35000, 45000, 40000, 40000, 65000, 50000, 50000, 75000],
'Color': ['White','White','White','Red','Blue','Blue','Yellow','Silver','Silver','Black','White','White','Black']
})
I am trying to merge cells in excel which has common values consecutively for a DataFrame df columns using the below mergecells function, however, when I open the excel file after merging it says the excel file has recovered some of the values.
def mergecells(df, columntomerge, sheetname, writer):
df1 = df.index.to_series().groupby(df[columntomerge]).agg(['first', 'last']).reset_index()
df1 = df1.sort_values("first").reset_index()
first_last_rows = df1.set_index('first')['last'].to_dict()
merge_ranges = {}
for key, value in first_last_rows.items():
if df.loc[key, columnname] in ["Alpha", "-"] or key == value:
continue
merge_ranges[df.loc[key, columnname]] = (
key 1, df.columns.get_loc(columnname), value 1, df.columns.get_loc(columnname))
wb = writer.book
ws = writer.sheets[sheetname]
mf = wb.add_format({'align': 'center', 'valign': 'vcenter'})
for name, merge_range in merge_ranges.items():
ws.merge_range(*merge_range, name, mf)
for col in df.columns:
mergecells(df,col,'Trial',writer)
But when I call the above merge function with the code above, I am getting the error as the below image
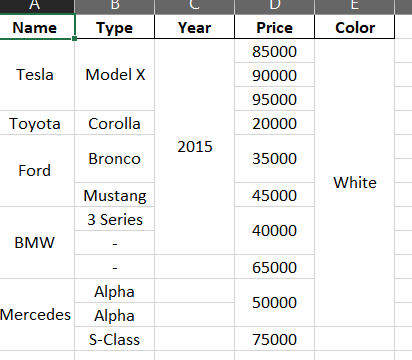
The Type column, Name column and Price column are correctly merged, However the Year and color are completely wrong
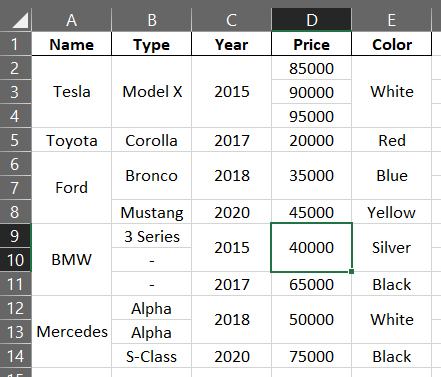
Expected Output
CodePudding user response:
The problem lies in the groupby. You have disjoint intervals while grouping by colors or year: White is found in rows [1, 2, 3] but also [11, 12]. You should consider consecutive values in a column. more_itertools.consecutive_groups can help you with that:
from more_itertools import consecutive_groups
sheetname='Sheet1'
with pd.ExcelWriter("test.xlsx") as writer:
df.to_excel(writer, sheet_name=sheetname, index=False)
wb = writer.book
ws = writer.sheets[sheetname]
mf = wb.add_format({'align': 'center', 'valign': 'vcenter'})
for j, col in enumerate(df.columns):
ws.set_column(j, j, 12, mf)
for val in df[col].unique():
idx = df[(df[col]==val) & (df[col]==df[col].shift(1))].index # indices of the rows where the value is the same as the previous row
for seg in consecutive_groups(idx):
l = list(seg)
ws.merge_range(l[0], j, l[-1] 1, j, val, mf)