I tried to clean the data as tabular by using pandas and the data is an excel file. The problem is merged row cell which is a type of data. I want to transpose it as a new column to classify the data.
What I'm Facing
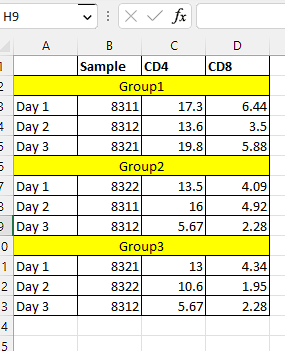
import pandas as pd
df = pd.read_excel('TestData.xlsx') # all data to df
# finding rows containing substring "Group" in the first column
indices = df[df['Unnamed: 0'].str.contains('Group')].index.tolist()
# creating empty dataframe for future data
masterDF = pd.DataFrame()
# looping initial dataframe
for i in range(len(indices)):
# slicing df from first indice to the last one
# or, in other words,
# reading the source excel file in chunks per each indice
try:
data = df.loc[indices[i]: indices[i 1] - 1, :].copy()
except IndexError:
data = df.loc[indices[i]:, :].copy()
# adding new Columns for each group
data['Group'] = data.iloc[0,0]
print(data.iloc[0,0])
print(data)
print('end_______________')
# now appending each chunk of data to the main dataframe
masterDF = pd.concat([masterDF, data])
# cleaning up dataframe before spitting out to .csv
masterDF.dropna(subset=['Sample', 'CD4', 'CD8'], how='all', inplace=True) # dropping rows with no data
masterDF.rename(columns={masterDF.columns[0]: ''}, inplace=True)
# spitting out the final data
masterDF.to_csv('output.csv', index=False)
out:
Sample CD4 CD8 Group
1 Day 1 8311.0 17.30 6.44 Group1
2 Day 2 8312.0 13.60 3.50 Group1
3 Day 3 8321.0 19.80 5.88 Group1
5 Day 1 8322.0 13.50 4.09 Group2
6 Day 2 8311.0 16.00 4.92 Group2
7 Day 3 8312.0 5.67 2.28 Group2
9 Day 1 8321.0 13.00 4.34 Group3
10 Day 2 8322.0 10.60 1.95 Group3
11 Day 3 8312.0 5.67 2.28 Group3