i want to train a logistic regression model on a dataset which has a categorical HomePlanet column contains 3 distinct values as : Earth , Europa , Mars
when i do :
pd.get_dummies(train['HomePlanet'])
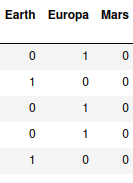
it seperates all categories as columns.Then i train the model with that dataset.
I can also make numerical categories by doing
train['HomePlanet'] = train['HomePlanet'].replace({'Earth':1 , 'Europa':2 , 'Mars':3 })

is it logical if i use the second way to convert the categorical data then train the model?
CodePudding user response:
The first approach is called 'One Hot Encoding' and the second is called 'Label Encoding'. Generally OHE is preferred over LE because LE can introduce the properties of similarity and ranking, when in fact these don't exist in the data.
Similarity - The idea that if categories are encoded with numbers that are closer to eachother, then they are more similar. In your example, one would expect Earth to be more similar to Europa than to Mars.
Ranking - Labels are assigned based on a specific order that is relevant to your problem, e.g size, distance, importance etc. For example in your case, you would be saying that Mars is bigger than Europa, and Europa is bigger than Earth.
I would say that in your example, one hot encoding will work better, but there are cases where label encoding makes more sense. For example to convert product reviews from "very bad, bad, neutral, good, very good" to "0,1,2,3,4" respectively. In this case, very good is the best option, so it is assigned a large number. Also very good is more similar to good than it is to very bad, therefore the number of very good (4) is closer to the number of good (3) than it is to very bad (0)