I have the following dataframe
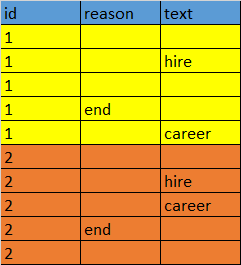
We want to count the no of times reason was ='end' after they encountered a keyword in another column . for eg the list of keywords are hire and career. So for case id '1' the 'end' was in the reason column after hire in text column . So hire gets a count of 1. In the second case , case id '2' the end was encoutered after both 'hire' and 'career', but career was the last one so the end was due to career and not hire. We need to take last keyword in the 'text' column as the probable reason for end.Hence 'career' nees a count of 1.We need to do this for each 'id'
Sample out put below

CodePudding user response:
If you forward fill the text column you can then dropna on the entire dataframe and the result will be the reason/text combos you want. You take the value counts of the remaining text columns and turn that into the df you want.
import pandas as pd
df = pd.DataFrame({'id':[1,1,1,1,1,2,2,2,2,2],
'reason':[np.nan,np.nan,np.nan,'end',np.nan,np.nan,np.nan,np.nan,'end',np.nan],
'text':[np.nan,'hire',np.nan,np.nan,'career',np.nan,'hire','career',np.nan,np.nan]})
output = (
df.assign(text=df['text'].ffill())
.dropna()
.text
.value_counts()
.to_frame('counts')
.T
)
print(output)
Output
hire career
counts 1 1