I have a large pandas dataframe that countains data similar to the image attached.
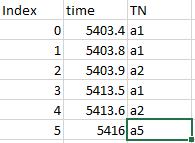
I want to get a count of how many unique TN exist within each 2 second window of the data. I've done this with a simple loop, but it is incredibly slow. Is there a better technique I can use to get this?
My original code is:
uniqueTN = []
tmstart = 5400; tmstop = 86400
for tm in range(int(tmstart), int(tmstop), 2):
df = rundf[(rundf['time']>=(tm-2))&rundf['time']<tm)]
uniqueTN.append(df['TN'].unique())
This solution would be fine it the set of data was not so large.
CodePudding user response:
Here is how you can implement groupby() method and nunique().
rundf['time'] = (rundf['time'] // 2) * 2
grouped = rundf.groupby('time')['TN'].nunique()
Another alternative is to use the resample() method of pandas and then the nunique() method.
grouped = rundf.resample('2S', on='time')['TN'].nunique()