hi i have create a DataFrame with pandas by a csv in this way
elementi = pd.read_csv('elementi.csv')
df = pd.DataFrame(elementi)
lst= []
lst2=[]
for x in df['elementi']:
a = x.split(";")
lst.append(a[0])
lst2.append(a[1])
ipo_oso = np.random.randint(0,3,76)
oso = np.random.randint(3,5,76)
ico = np.random.randint(5,6,76)
per_ico = np.random.randint(6,7,76)
df = pd.DataFrame(lst,index=lst2,columns=['elementi'])
# drop the element i don't use in the periodic table
df = df.drop(df[103:117].index)
df = df.drop(df[90:104].index)
df = df.drop(df[58:72].index)
df.head()
df['ipo_oso'] = ipo_oso
df['oso'] = oso
df['ico'] = ico
df['per_ico'] = per_ico
df.to_csv('period_table')
df.head()
and looks like this
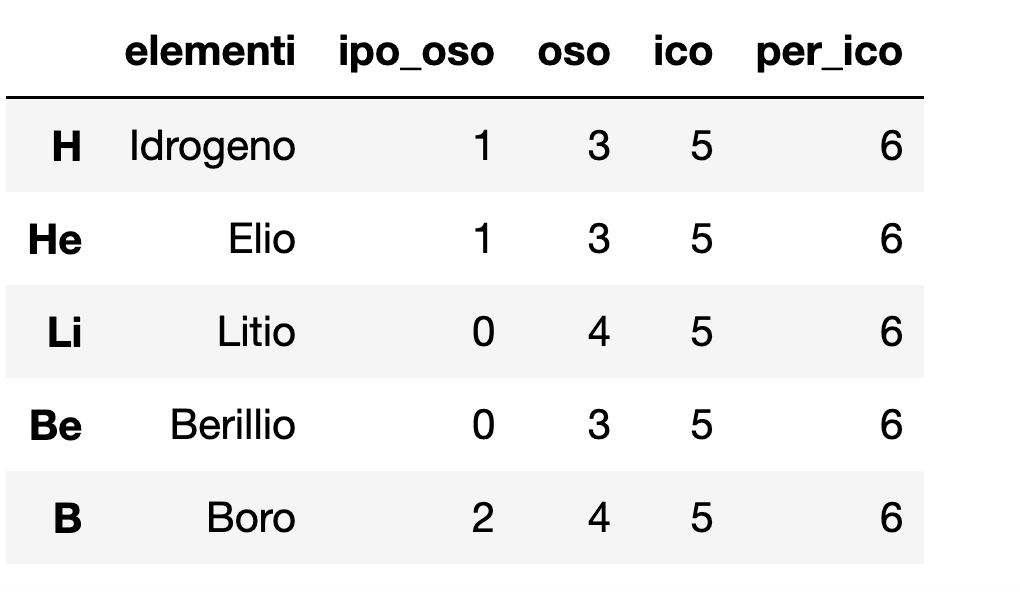
when i save this table with to_csv() and import it in another project with read_csv() the index of table is considered as a column but is the index
e= pd.read_csv('period_table')
e.head()
or
e= pd.read_csv('period_table')
df =pd.DataFrame(e)
df.head()
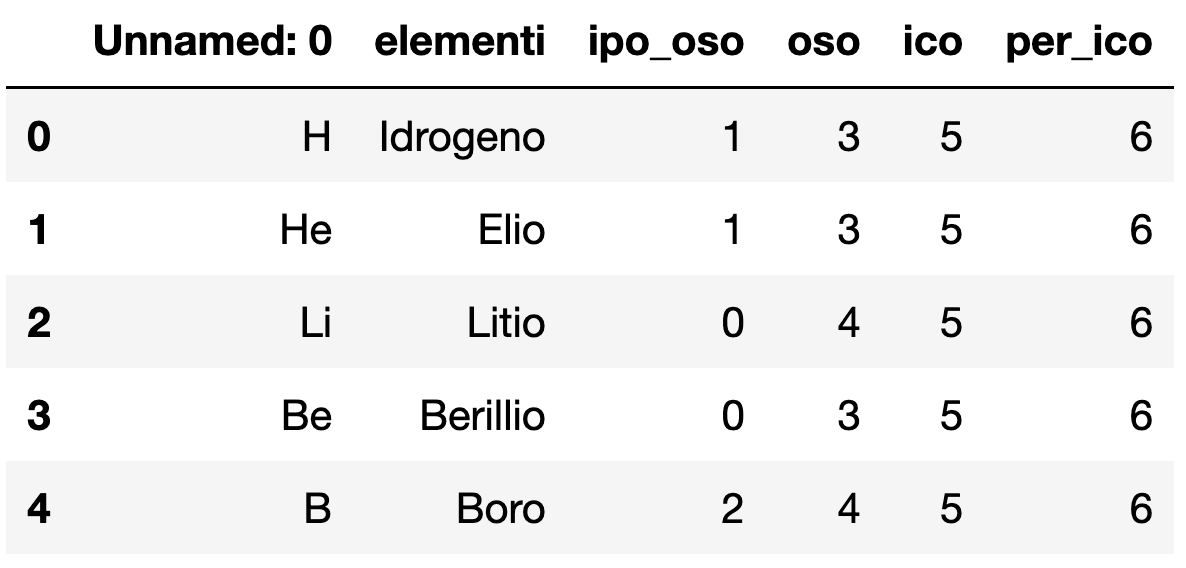
how can i fix that :)
CodePudding user response:
Just use index_col=0 as parameter of read_csv:
df = pd.read_csv('period_table', index_col=0)
df.head()