I have a multi-level column dataframe on the lines of one below:
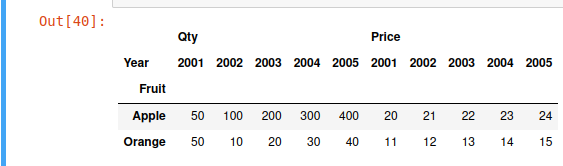 How can I add columns 'Sales' = 'Qty' * 'Price' one each for each 'Year'?
How can I add columns 'Sales' = 'Qty' * 'Price' one each for each 'Year'?
The input dataframe in dictionary format:
{('Qty', 2001): [50, 50], ('Qty', 2002): [100, 10], ('Qty', 2003): [200, 20], ('Qty', 2004): [300, 30], ('Qty', 2005): [400, 40], ('Price', 2001): [20, 11], ('Price', 2002): [21, 12], ('Price', 2003): [22, 13], ('Price', 2004): [23, 14], ('Price', 2005): [24, 15]}
Currently, I am splitting the dataframe for each year separately and adding a computed column. If there is an easier method that would be great.
Here is the expected output
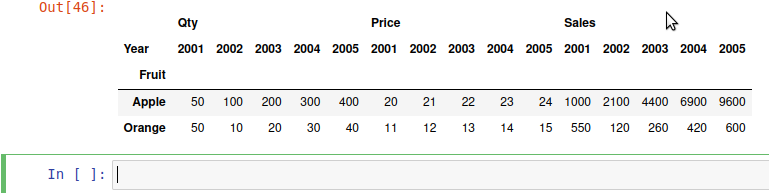
CodePudding user response:
You can create the required column names with a list comprehension, and then simply assign the multiplication (df.mul).
new_cols = [('Sales', col) for col in df['Qty'].columns]
# [('Sales', 2001), ('Sales', 2002), ('Sales', 2003), ('Sales', 2004), ('Sales', 2005)]
df[new_cols] = df['Qty'].mul(df['Price'])
df
Qty Price Sales \
2001 2002 2003 2004 2005 2001 2002 2003 2004 2005 2001 2002 2003 2004
0 50 100 200 300 400 20 21 22 23 24 1000 2100 4400 6900
1 50 10 20 30 40 11 12 13 14 15 550 120 260 420
2005
0 9600
1 600
CodePudding user response:
Let us stack to flatten multiindex columns then multiply and reshape back using unstack
df.stack().eval('Sales = Price * Qty').unstack()
Price Qty Sales
2001 2002 2003 2004 2005 2001 2002 2003 2004 2005 2001 2002 2003 2004 2005
0 20 21 22 23 24 50 100 200 300 400 1000 2100 4400 6900 9600
1 11 12 13 14 15 50 10 20 30 40 550 120 260 420 600