Simply write a crawler, visit scrapy official tutorial page, all the author want to extract the home page, the HTML code is as follows:
import scrapy
The class Quote_Spider (scrapy. Spiders) :
Name='quotes'
Allowed_domains=[' http://quotes.toscrape.com/']
Start_urls=[' http://quotes.toscrape.com/']
Def parse (self, response) :
The content=response. Xpath ("//div [@ class='col - md - 8] ")
Print (" 8 "* 30)
Print (content [0]. Extract ())
Print (' * '* 30)
Print (content [0]. Xpath ("//div//small/text () "). The extract ())
The content list should include two selector, and one of the content of the authors extract [0] does not contain elements, content [1] is contained and can successfully extracted, then why the content [0] does not contain the author element, obviously I can filter out,,,,,, crazy, and execute the following screenshot:
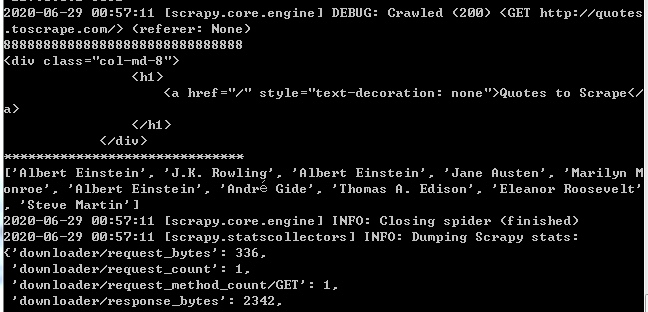
CodePudding user response:
No, problem solvedCodePudding user response:
No, problem solved