Failed to find the corresponding plate, a temporary release here, the goal is to make everyone to 0, can read,
at present, my amateur football data gleaned from mining work, establish the data set with moddler c5.0 to operation, the results are as follows:
The results of the training set and validation set is as follows:
The total number of more than 885 70% training, verification of 30%,
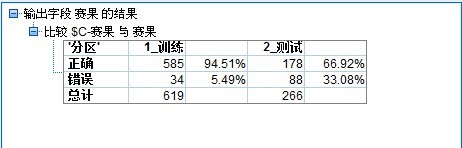
As shown in the above, there is a training set fitting,
Operation results, the predicted result and forecast result credibility sample below,
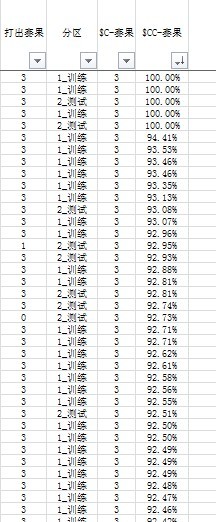
My question is:
First, the training set validation set above mixed results, can be used as a practical prediction based on? Because both the training set and validation set, some games tool predicted results corresponding to the credibility of the still high (94% training set, of course, there must be a fitting), but the validation set 2 high credibility can be used as a prediction based on?
Second, there is a very interesting finding, if do not do partition, the 885 data modeling directly, also don't consider the question of whether or not to over fitting, the results show that the predictions credibility is lower than 80%, and the following, if the following
:
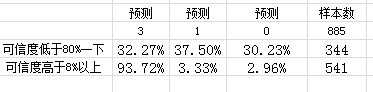
That is to say, regardless of whether or not a fitting c5.0 run results, as long as the credibility of over 80%, the main winning probability at 93%, three radio (total 885 against, wins at less than 2.0), while the credibility under 80% of the games, the probability of 3, 0 three results are similar, indicated that once predicted credibility is lower than 80%, this game can be the whole package, very magical, is also very puzzled,
Wonder: not considered fit or not, the above results suggest a problem, c5.0 against, the 885 valid is divided into two categories, namely a class of type 3 is higher, the result of a whole package best,
the above according to the analysis of basic data mining think many contradictions - such as a fitting problem, but even under the condition of fitting, computation results are given an unexpected "surprise" of "classification",
The above, I do not know what explanation?