defect is easy to cause the data volume is too big to climb take lost parts of time travel, adding more troublesome
The import urllib. Request
The import time
The from bs4 import BeautifulSoup
The class areaClass:
Def fn (self) :
Indexs='index.html'
Url='http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
TXT=urllib. Request. Urlopen (url + indexs). The read (). The decode (' GBK ')
Soup=BeautifulSoup (TXT, '. The HTML parser)
Lista=soup. Find_all (' a ')
Lista. Pop ()
For a in lista:
# output province
Print (" s_ + a "[' href '] [2-0] +" "+ a.t ext)
Time. Sleep (1)
TXT=urllib. Request. Urlopen (url + [' href '], a timeout=5000). The read (). The decode (' GBK ')
Soup=BeautifulSoup (TXT, '. The HTML parser)
By=soup. Find_all (' a ')
By the pop ()
Bb={}
L=len (by)
# print (" -- -- -- -- -- & gt;>> "+ STR (l/2) +" & lt; <<<-- -- -- -- -- - ")
StrName='
For I in range (0, 1) l:
If (by [I]. Text==strName) :
The continue
StrIndex=by [I] [' href ']
Code=by [I]. Text
Codecity=code
StrName=name=by [I + 1] text
# print (strIndex + + code ", "+", "+ name)
# output municipal
Print (code + "" + name +" s_ "+ strIndex [2-0])
Street # # url address
Url2=url + strIndex [2-0] + '/'
Time. Sleep (1)
Try:
CTXT=urllib. Request. Urlopen (url + strIndex, timeout=5000). The read (). The decode (' GBK ')
Soup=BeautifulSoup (CTXT, '. The HTML parser)
Listc=soup. Find_all (' a ')
Listc. Pop ()
Lc=len (listc)
# print (" -- -- -- -- -- & gt;>> "+ STR (lc/2) +" & lt; <<<-- -- -- -- -- - ")
CstrName='
For c in range (0, lc - 1) :
If (listc [c]. Text==cstrName) :
The continue
StrIndex=listc [c] [' href ']
Code=listc [c]. Text
CodeArea=code
CstrName=name=listc [c + 1] text
# output district-level
Print (code + "" + name +" "+" "+ codecity)
# the streets
Self. Fn2 (url2 + strIndex codeArea, url2 + strIndex [2-0] + '/')
Except:
Print (" ")
The continue
# neighborhood
Def fn3 (self, url, codejd) :
CTXT=urllib. Request. Urlopen (url, timeout=5000). The read (). The decode (' GBK ')
Soup=BeautifulSoup (CTXT, '. The HTML parser)
Listc=soup. Find_all (" td ")
Listc. Pop ()
Lc=len (listc)
CstrName='
For c in range (8, lc - 1) :
# print (listc [c]. Text + "p======" + cstrName + "=======p)
If (listc [c]. Text==cstrName) :
The continue
Code=listc [c]. Text
CstrName=name=listc + 2 [c]. Text
# neighborhood data there are problems here, don't study for a while. According to you need to configure
# output neighborhood
Print (code + "-" + name + "" +" - "+ codejd +" br ")
# the streets
Def fn2 (self, url, codeArea, url2) :
CTXT=urllib. Request. Urlopen (url, timeout=5000). The read (). The decode (' GBK ')
Soup=BeautifulSoup (CTXT, '. The HTML parser)
Listc=soup. Find_all (' a ')
Listc. Pop ()
Lc=len (listc)
CstrName='
For c in range (0, lc - 1) :
If (listc [c]. Text==cstrName) :
The continue
StrIndex=listc [c] [' href ']
Code=listc [c]. Text
Codejd=code
CstrName=name=listc [c + 1] text
# output streets
Print (code + "" + name +" "+" "+ codeArea)
# self. Fn3 (url2 + strIndex, codejd)
AreaBl=areaClass () # variable object
AreaBl. Fn ()
2. According to the province way to crawl, in Beijing, for example code is as follows:
network request is not stable, will also be the case of few data is missing, so you need to check again with crawl. On the basis of 3 according to the city's data quantity, less is more easy to crawl
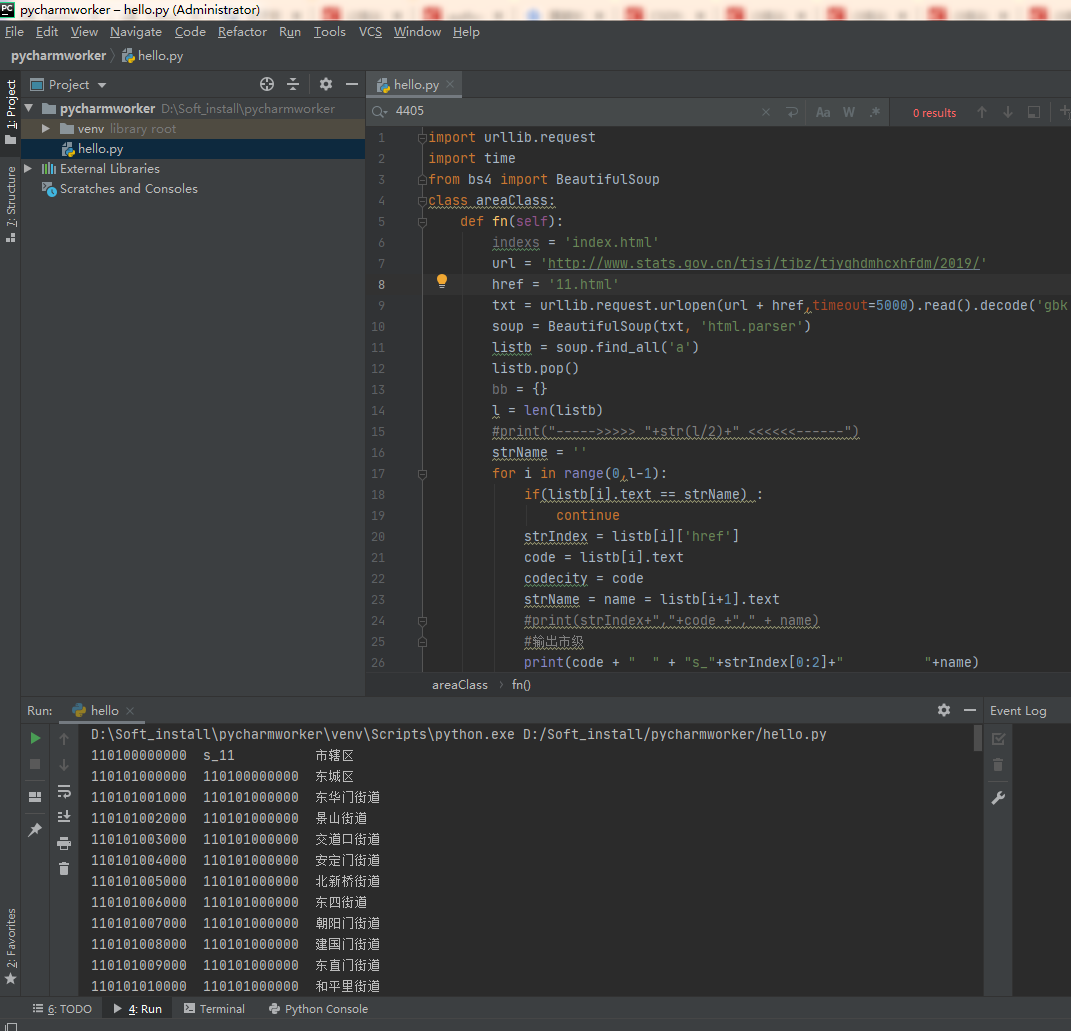
The import urllib. Request
The import time
The from bs4 import BeautifulSoup
The class areaClass:
Def fn (self) :
Indexs='index.html'
Url='http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
Href='https://bbs.csdn.net/topics/11.html'
TXT=urllib. Request. Urlopen (url + href, timeout=5000). The read (). The decode (' GBK ')
Soup=BeautifulSoup (TXT, '. The HTML parser)
By=soup. Find_all (' a ')
By the pop ()
Bb={}
L=len (by)
# print (" -- -- -- -- -- & gt;>> "+ STR (l/2) +" & lt; <<<-- -- -- -- -- - ")
StrName='
For I in range (0, 1) l:
If (by [I]. Text==strName) :
The continue
StrIndex=by [I] [' href ']
Code=by [I]. Text
Codecity=code
StrName=name=by [I + 1] text
# print (strIndex + + code ", "+", "+ name)
# output municipal
Print (code + "" +" s_ "+ strIndex [2-0] +" "+ name)
Street # # url address
Url2=url + strIndex [2-0] + '/'
Time. Sleep (1)
Try:
CTXT=urllib. Request. Urlopen (url + strIndex, timeout=5000). The read (). The decode (' GBK ')
Soup=BeautifulSoup (CTXT, '. The HTML parser)
Listc=soup. Find_all (' a ')
Listc. Pop ()
Lc=len (listc)
# print (" -- -- -- -- -- & gt;>> "+ STR (lc/2) +" & lt; <<<-- -- -- -- -- - ")
CstrName='
For c in range (0, lc - 1) :
If (listc [c]. Text==cstrName) :
The continue
StrIndex=listc [c] [' href ']
Code=listc [c]. Text
CodeArea=code
CstrName=name=listc [c + 1] text
# output district-level
Print (code + "" + codecity +" "+ name)
# the streets
nullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull