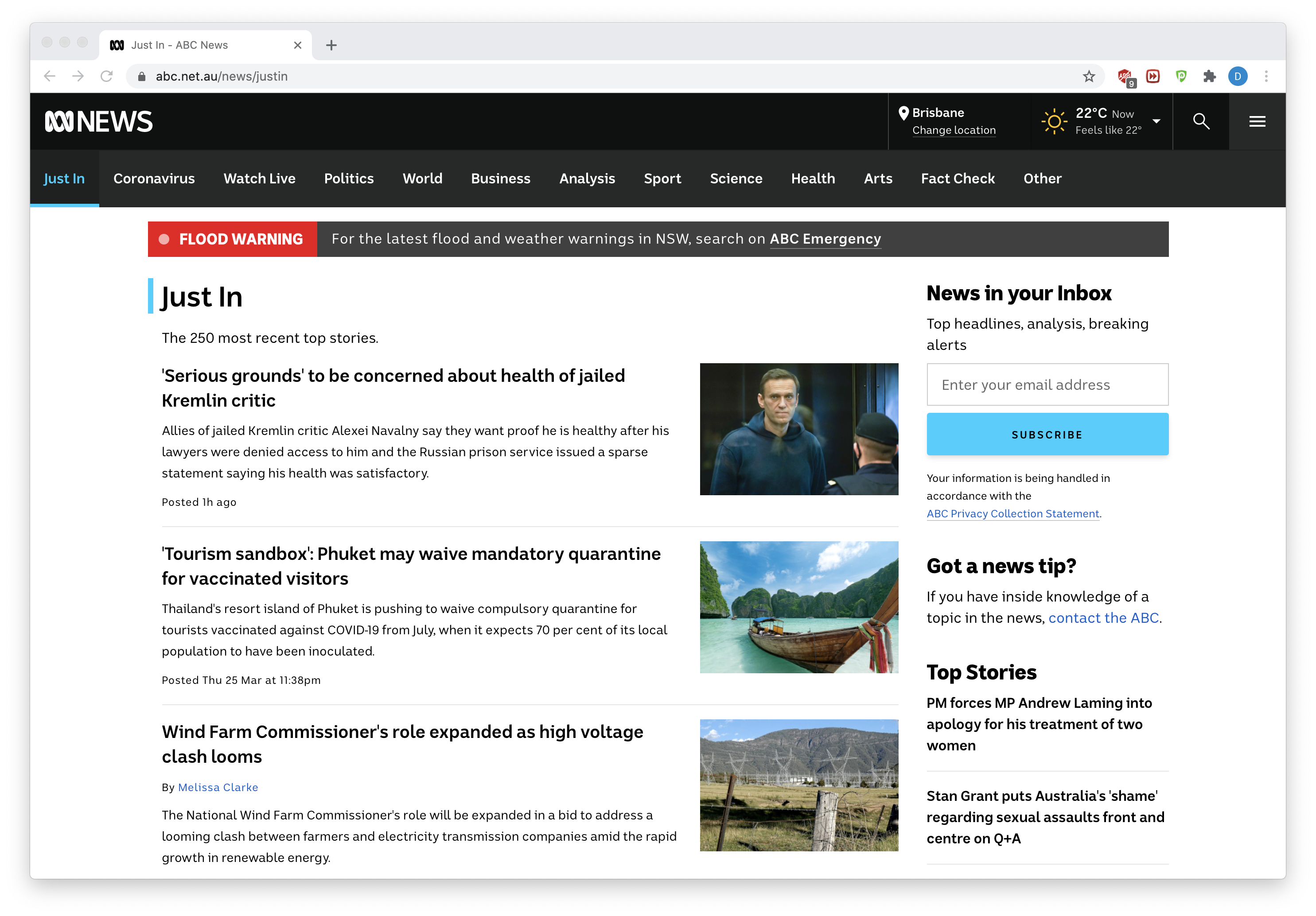
We are Just interested in part of the news headlines and links, and more specifically, this is highlighted in this
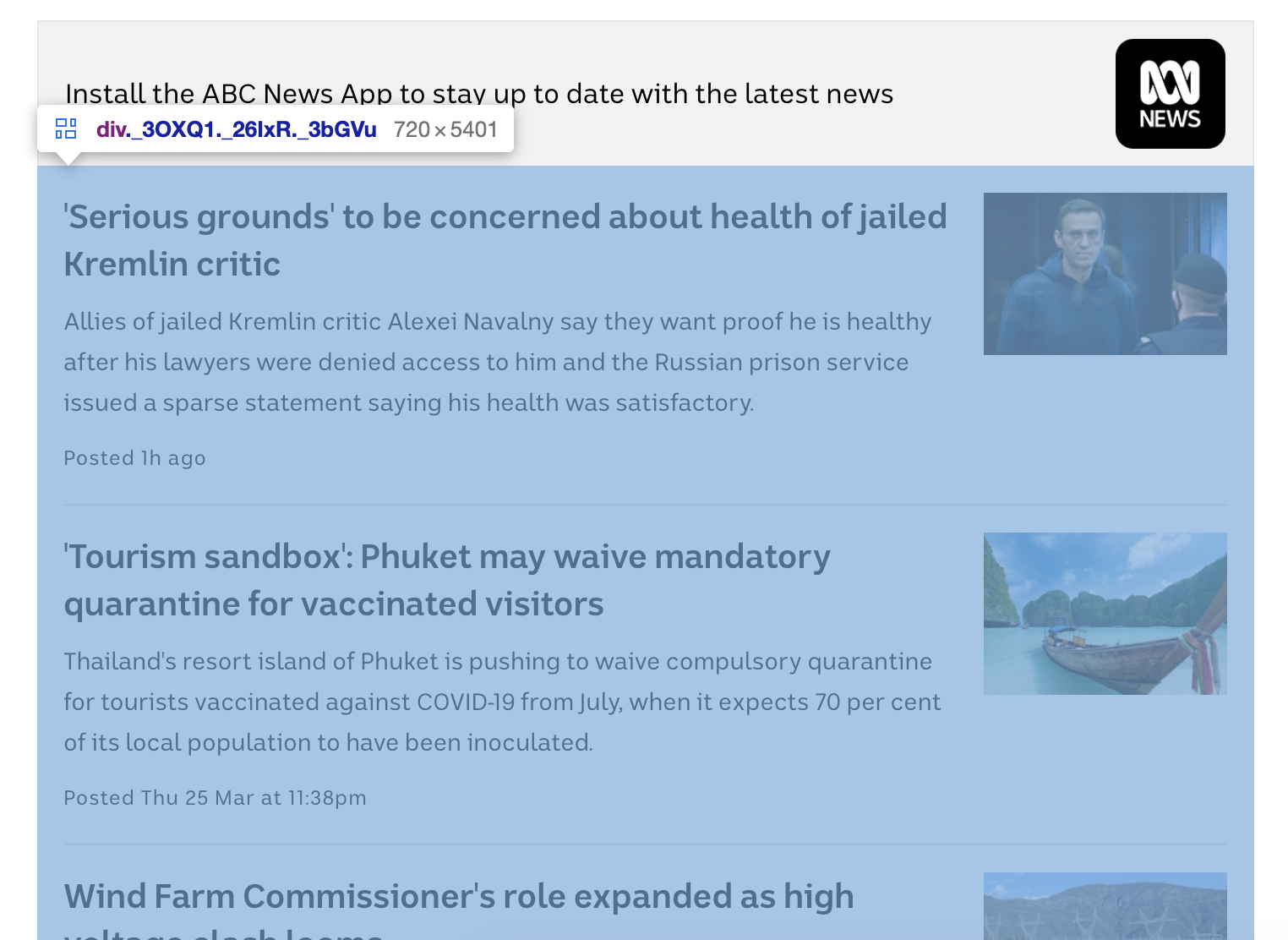
Since this exercise published on the page content has been updated, and despite the changes in the content, but the principle remains the same,
You need to do is: in Just in highlighted part of the page to gather all (1) the title, (2) the underlying hyperlinks and (3) the description of the news articles, to save information to a group called abcnews. CSV CSV file, the file contains three variables: title, link and "description", each article, in combination with the title of the article, link and description,
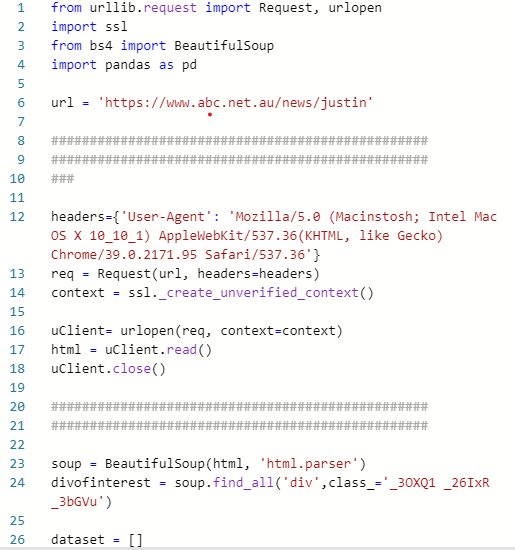

The from urllib. Request the import request, urlopen
The import SSL
The from bs4 import BeautifulSoup
The import pandas as pd
Url='https://www.abc.net.au/news/justin'
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # #
Headers={' the user-agent ':' Mozilla/5.0 (Macinstosh; Intel Mac OS X 10 _10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 '}
The req=Request (url, headers=headers)
The context=SSL. _create_unverified_context ()
UClient=urlopen (the req, context=context)
HTML=uClient. Read ()
UClient. Close ()
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
Soup=BeautifulSoup (HTML, '. The HTML parser)
Divofinterest=soup. Find_all (' div 'class_=' _3OXQ1 _26IxR _3bGVu ')
The dataset=[]
For the item in divofinterest (' a ') :
Title=item. The find (" p "). The getText ()
Url=item [' href ']
Print (the title)
Print (url)
Print ()
The dataset. Append ({' title: the title, 'url: url})
The dataset=pd. DataFrame (dataset)
The dataset. To_csv (' abcnews. CSV, sep='; ', the index=False)
Now write this