I would like to parse a table using BS and ultimately put some if its content into a dataframe. For tables there is only one line of text in each row this works fine.
There are however cases where some tables cells contain multiple lines of text. One of those examples looks like this: 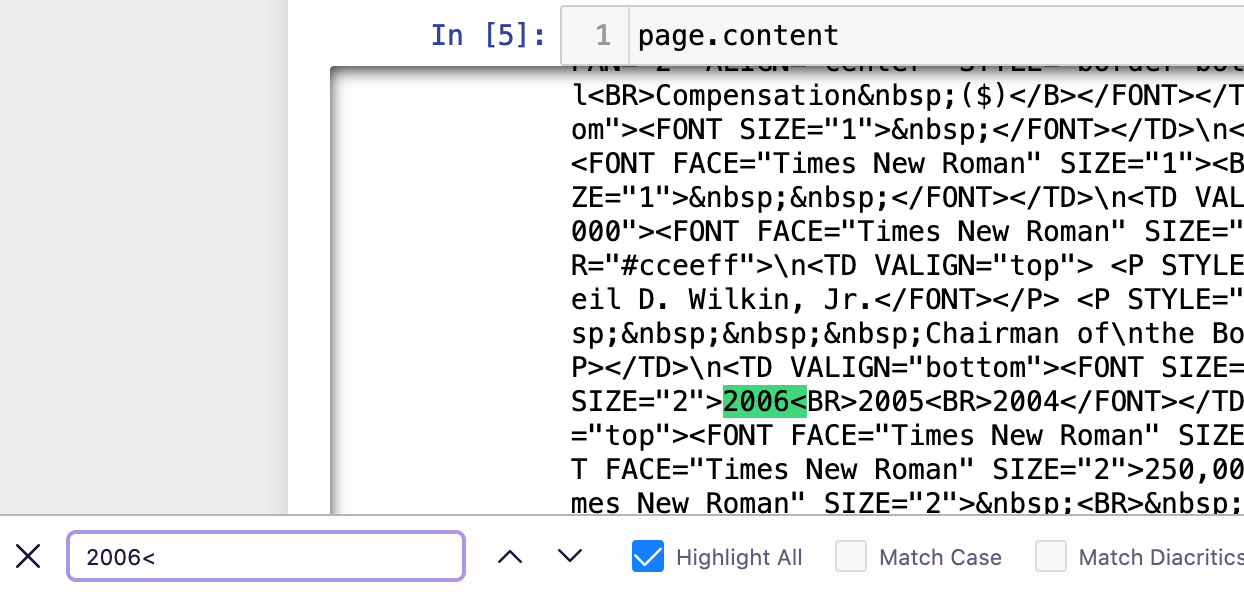
So...
Maybe:
import pandas as pd
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.3"
}
url = 'https://www.sec.gov/Archives/edgar/data/0001000230/000119312507035211/ddef14a.htm'
page = requests.get(url, headers=headers)
tables = pd.read_html(page.text.replace('<BR>','\n'))
df = pd.DataFrame(tables[50])
# df.columns = pd.MultiIndex.from_arrays([df.iloc[1],df.iloc[2]])
# line above or the line below - pick one, comment the other out
df.columns = df.iloc[2]
df = df.iloc[3:]
df = df.reset_index(drop=True)
df = df.dropna(axis=1)
df = df.loc[:,~(df=='$').any()]
display(df)
Output:
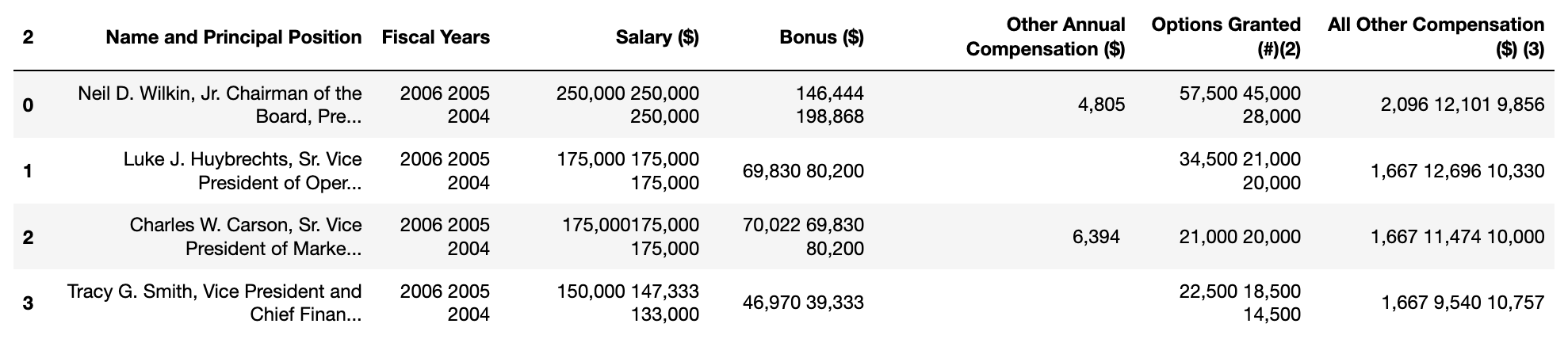
Exporting:
from styleframe import StyleFrame
StyleFrame(df).to_excel('out.xlsx').save()
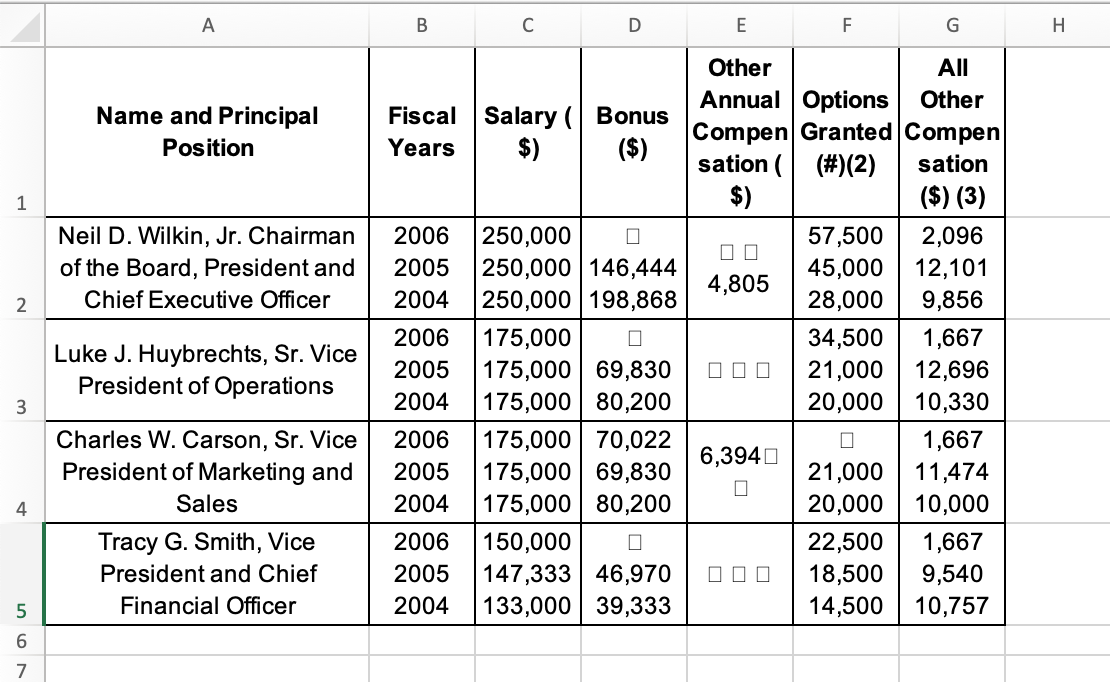
Seems that those squares are some \x97 chars in there you can obviously remove when cleaning it up.