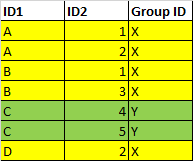
I'm trying to add a key for all related instances between two columns, then create a GroupID
The logic will be:
- Check all instances of ID2 linked to ID1
- CHeck all instances of ID1 linked to ID2 found in (1)
- Repeat until all relationships found
CodePudding user response:
Let us try with networkx
import networkx as nx
G=nx.from_pandas_edgelist(df, 'ID1', 'ID2')
l=list(nx.connected_components(G))
L=[dict.fromkeys(y,x) for x, y in enumerate(l)]
d={k: v for d in L for k, v in d.items()}
df['new'] = df['ID1'].map(d)
df
Out[302]:
ID1 ID2 new
0 A 1 0
1 A 2 0
2 B 1 0
3 B 3 0
4 C 4 1
5 C 5 1
6 D 2 0