I have a sample dataframe as given below.
import pandas as pd
data = {'ID':['A', 'A', 'A','A','A','A' ,'B','B','B','B','B'],
'Date':['2021-09-20 04:34:57', '2021-09-20 04:37:25', '2021-09-22 04:38:26', '2021-09-23
00:12:29','2021-09-22 11:20:58','2021-09-25 09:20:58','2021-03-11 21:20:00','2021-03-
11 21:25:00','2021-03-12 21:25:00', '2021-03-13 21:25:00', '2021-03-15 21:25:00']}
df1 = pd.DataFrame(data)
df1
The snippet of it is given below. The 'Date' column is in Datetime format.
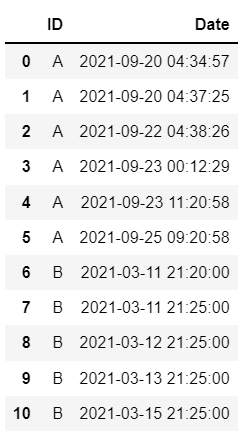
Now, I want to find the total number of missing dates in between for each participant and print them(or create a new dataframe).
ID Missing days
A 3 (21st,22nd and 24th September dates missing)
B 1 (14th march missing)
Any help is greatly appreciated. Thanks.
CodePudding user response:
Answer below will fail with multiple consecutive missing days (Thanks Ben T). We can solve this by using resample per group, than count the NaT:
dfg = df1.groupby("ID").apply(lambda x: x.resample(rule="D", on="Date").first())
dfg["Date"].isna().sum(level=0).reset_index(name="Missing days")
ID Missing days
0 A 2
1 B 1
** OLD ANSWER **
We can use GroupBy.diff and check how many diffs are greater than 1 day:
df1["Date"] = pd.to_datetime(df1["Date"])
(
df1.groupby("ID")["Date"]
.apply(lambda x: x.diff().gt(pd.Timedelta(1, "D")).sum())
.reset_index(name="Missing days")
)
ID Missing days
0 A 2
1 B 1