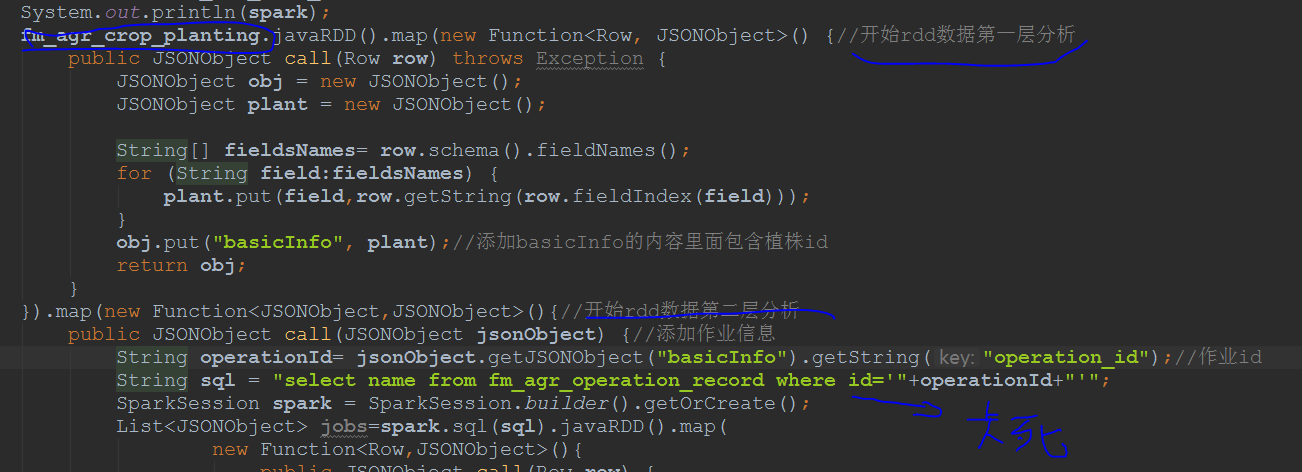
Current practice is to first read out the data, save into a temporary table, then through the map of RDD hierarchical processing, each layer of the data you need to specify in the temporary table to pick up, finished the test code, find work ah, as long as you go in the next layer in the temporary table lookup data are jammed, have a great god give a solution, thank you, the current analysis code is as follows:
Console the last information is as follows:

Ever know how to tell what is bai.
CodePudding user response:
Gosh, another in creating SparkSession operatorCodePudding user response:
All data read into dataframe first, and then through the filter and the join, drop dataframe operator get what they want