I have csv file, which contains missing column values, how to copy missing column value from previous row ?
product_id,name,modifier
1,test,cheese
,test,eggs
,test,onions
2,test2,cheese
,test2,eggs
,test2,onions
Above CSV data, gets below output
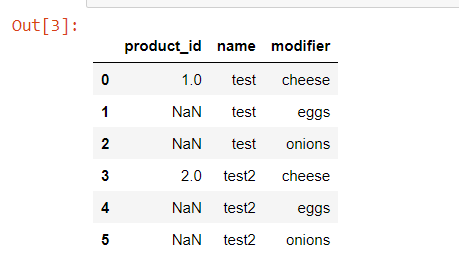
import pandas as pd
import numpy as np
df = pd.read_csv("pivot-products.csv")
df.pivot(index='product_id',columns='modifier') # <-- throws error
Above pivot code works fine with below dataset, where I manually copied it, how to cleanup in pandas to look like below ?
product_id,name,modifier
1,test,cheese
1,test,eggs
1,test,onions
2,test2,cheese
2,test2,eggs
2,test2,onions
CodePudding user response:
Try using ffill. For example:
df = pd.read_csv("pivot-products.csv")
df["product_id"] = df["product_id"].ffill()
CodePudding user response:
Try:
df['product_id'].ffill(inplace=True)
CodePudding user response:
but look specifically for the method='ffill' option
CodePudding user response:
df.fillna(mehtod='ffill').fillna(value)
You do fillna twice because the 'ffill' will fail to fill nan values in the first row. You can define the value.