I'm working on this raw data frame that needs some cleaning. So far, I have transformed this xlsx file
into this pandas dataframe:
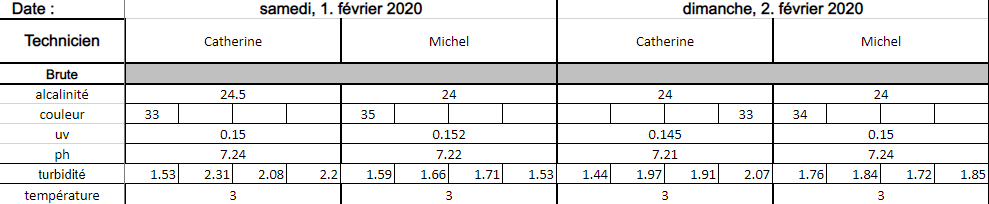
print(df.head(16))
date technician alkalinity colour uv ph turbidity \
0 2020-02-01 00:00:00 Catherine 24.5 33 0.15 7.24 1.53
1 Unnamed: 2 NaN NaN NaN NaN NaN 2.31
2 Unnamed: 3 NaN NaN NaN NaN NaN 2.08
3 Unnamed: 4 NaN NaN NaN NaN NaN 2.2
4 Unnamed: 5 Michel 24 35 0.152 7.22 1.59
5 Unnamed: 6 NaN NaN NaN NaN NaN 1.66
6 Unnamed: 7 NaN NaN NaN NaN NaN 1.71
7 Unnamed: 8 NaN NaN NaN NaN NaN 1.53
8 2020-02-02 00:00:00 Catherine 24 NaN 0.145 7.21 1.44
9 Unnamed: 10 NaN NaN NaN NaN NaN 1.97
10 Unnamed: 11 NaN NaN NaN NaN NaN 1.91
11 Unnamed: 12 NaN NaN 33.0 NaN NaN 2.07
12 Unnamed: 13 Michel 24 34 0.15 7.24 1.76
13 Unnamed: 14 NaN NaN NaN NaN NaN 1.84
14 Unnamed: 15 NaN NaN NaN NaN NaN 1.72
15 Unnamed: 16 NaN NaN NaN NaN NaN 1.85
temperature
0 3
1 NaN
2 NaN
3 NaN
4 3
5 NaN
6 NaN
7 NaN
8 3
9 NaN
10 NaN
11 NaN
12 3
13 NaN
14 NaN
15 NaN
From here, I want to combine the rows so that I only have one row for each date. The values for each row will be the mean in the respective columns. ie.
print(new_df.head(2))
date time alkalinity colour uv ph turbidity temperature
0 2020-02-01 00:00:00 24.25 34 0.151 7.23 1.83 3
1 2020-02-02 00:00:00 24 33.5 0.148 7.23 1.82 3
How can I accomplish this when I have Unnamed values in my date column? Thanks!
CodePudding user response:
Try setting the values to NaN and then use ffill:
df.loc[df.date.str.contains('Unnamed', na=False), 'date'] = np.nan
df.date = df.date.ffill()
CodePudding user response:
If I understand, correctly you want to drop rows that contain 'Unnamed' in the date column, right?
Please look here: https://stackoverflow.com/a/27360130/12790501
The solution would be something like this:
df = df.drop(df['Unnamed' in df.date].index)
Edit:
No, I would like to replace those Unnamed values with the date so I could then use the groupby('date') function to return the mean values for the columns
so in the case you should just iterate over the whole table
last_date = ''
for i in df.index:
if 'Unnamed' not in df.at[i, 'date']:
last_date = df.at[i, 'date']
else:
df.at[i, 'date'] = last_date
CodePudding user response:
If the 'date' column is of type object i.e. string then just write a logic to loop over the number as seen in image provided it follows a certain pattern-
for _ in range(2,9):
df.loc[(df['date'] == 'Unnamed: ' str(_), 'date'] = your_value