I am taking data from two input Excel files and processing them with the help of pandas dataframe. Excel has large data and number of columns. However I have created simple examples to illustrate this question
Following is first dataframe df_s1(action needs to perform on Part Number Column)-
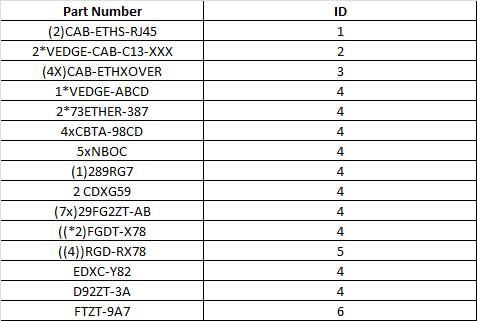
Following is second dataframe df_s2(here some special charaters are mentioned and I have to remove these characters only from starting of df_s1['Part Number'], These characters are very large including , 2, ((*2) etc... I have mentioned limited)-

I want following output after processing df_s1 with the help of df_s2-
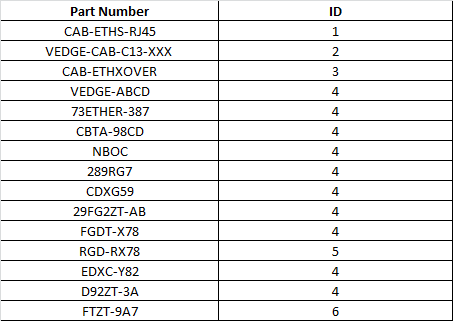
Now problem statement is I have to delete(remove) all the special characters only from starting of column Part Number in df_s1(first dataframe). Information about these special characters are mentioned in df_s2(second dataframe Special Character Column(large number of characters including(,*...)
I have tried following code to achieve it. Also I have prepared sample dataframes in my code so that it will be easy for solution)
#first dataframe and remove special charaters from starting of part number column
import pandas as pd
df_s1 = pd.DataFrame({'Part Number' : ['(2)CAB-ETHS-RJ45',' 2*VEDGE-CAB-C13-XXX','(4X)CAB-ETHXOVER','1*VEDGE-ABCD','2*73ETHER-387','4xCBTA-98CD','5xNBOC','(1)289RG7','2 CDXG59','(7x)29FG2ZT-AB','((*2)FGDT-X78','((4))RGD-RX78','EDXC-Y82','D92ZT-3A','FTZT-9A7'],
'ID' : ['1','2','3','4','4','4','4','4','4','4','4','5','4','4','6']
})
#Following special charaters needs to remove from starting of part number column of first dataframe
df_s2 = pd.DataFrame({'Special Charater':['(2)','2*','(4X)','1*','4x','5x','(1)','2 ','(7x)','((*2)','((4))']})
for i in df_s2['Special Charater']:
j=0
for k in df_s1['Part Number']:
if str(k).startswith(str(i)):
df_s1['Part Number'][j] = str(k[len(i):])
else:
j =1
df_s1
However I am getting following required output from above code except 1 part number 2*VEDGE-CAB-C13-XXX in which 2* is not removed
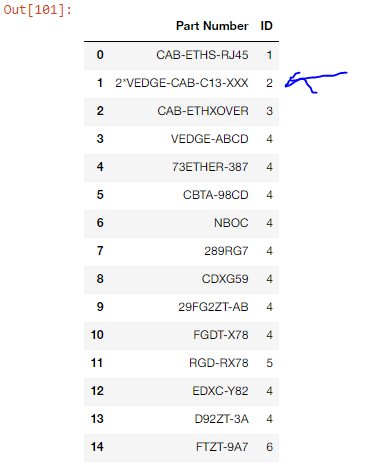
I am looking for-
- I know it is not standard way to achieve this task through pandas. So could you please help me with your pandas python solution for it like
df.str.findall().str.replace(). I am unable to put this type of standard approach in my solution. Just we have to replace all characters mentioned as it is in second dataframe from starting of first dataframe part number column - I am not able to figure out the reason why
2*VEDGE-CAB-C13-XXX2* is not removed from starting in my solution while other special character removes from starting
Hope I am clear and very positive to get another approach of this problem
CodePudding user response:
You could define a regular expression and use the pandas replace option.
As far as I see, you want to repalce all elements before an asterix *, an empty space an x or a closing bracket ). The code below trys to find 1 match at most, beginning on the left side of the string.
df_s1['Part Number'].str.replace('(.*[x| |\)|*])', '', n=1)
Older attempt
You could try the code below, because you know all the strings you want to replace. In this case, you loop over each string multiple times, and if you find an unwanted substring you substitute the string with an empty one.
def replace(x):
for item in ['(2)','2*','(4X)','1*','4x','5x','(1)','2 ','(7x)','((*2)','((4))']:
x = x.replace(item, '')
return x
df_s1['Part Number'].apply(replace)
CodePudding user response:
You can try out this code for an alternate solution:
import re
for sp_char in df_s2['Special Character']:
df_s1['Part Number'] = df_s1['Part Number'].replace({re.escape(sp_char): ""}, regex=True)
print(df_s1)
The re.escape() is specifically used to add backslashes to all special characters (which might be the reason why some solutions you tried are not working)
Also, this code can probably be simplified further to make it more optimised, but for now this should give you the required output. Will update my answer in the future if I can think of something more optimised...