I have a list of html files that contain a certain tag in each file as below:
<div id="myID" style="display:none">1_34876</div>
I would like to search for that tag in each file and rename each file according to the number within that tag, i.e rename the file containing the tag above to 1_34876.html and so forth..
Is there a regex or bash command using grep or awk that can accomplish this?
So far I was able to grep each file using the following command but stuck on how to rename the files:
grep '<div id="myID" style="display:none">.*</div>' ./*.html
An additional bonus would be if the command doesn't overwrite duplicate files, e.g. if another file contains the 1_34876 tag above then the second file would be renamed as 1_34876 v2.html or something similar.
Kindly advice if this can be achieved in a way that doesn't require programming.
Many thanks indeed. Ali
CodePudding user response:
You can use the following script to achieve your goal. Note, for the script to work on macOS, you either have to install GNU grep via Homebrew, or substitute the grep call with ggrep.
- The script will search the current directory and all its subdirectories for
*.htmlfiles. - It will substitute only the names of the files that contain the specific tag.
- For multiple files that containt the same tag, each subsicuent file apart from the first will have an identifier appended to its name. E.g.,
1_234.html,1_234_1.html,1_234_2.html - For files that contain multiple tags, the first tag encountered will be used.
#!/bin/bash
rename_file ()
{
# Check that file name received is a non zero string
file_name="$(realpath "${1}")"
if [ -f "${file_name}" ]; then
echo "No argument or non existing file or non regular file provided"
exit 1
fi
# Get the tag number. If the number does not exist, the variable tag will be
# empty. The first tag on a file will be used if there are multiple tags
# within a file.
tag="$(grep -oP -m 1 '(?<=<div id="myID" style="display:none">).*?(?=</div>)' \
-- "${file_name}")"
# Rename the file only if it contained a tag
if [ ! -z "${tag}" ]; then
file_path="$(dirname "${file_name}")"
# Change directory to the file's location silently
pushd "${file_path}" > /dev/null
# Check for multiple occurences of files with the same tag
if [ -e "${tag}.html" ]; then
counter="$(find ./ -maxdepth 1 -type f -name "${tag}.html" -o -name "${tag}_*.html" | wc -l)"
tag="${tag}_${counter}"
fi
# Rename the file
mv "${file_name}" "${tag}.html"
# Return to previous directory silently
popd > /dev/null
fi
}
# Necessary in order to call rename_file from find command within main
export -f rename_file
# The entry point function of the script. This function searches for all the
# html files in the directory that the script is run, and all subdirectories.
# The function calls rename_files upon each of the found files.
main ()
{
find ./ -type f -name "*.html" -exec bash -c 'rename_file "${1}"' _ {} \;
}
main
CodePudding user response:
Solution :
# create test files
rm *.html
echo '<div id="myID" style="display:none">1_1</div>' > 1.html
echo '<div id="myID" style="display:none">1_2</div>' > 2.html
# loop throught matching files
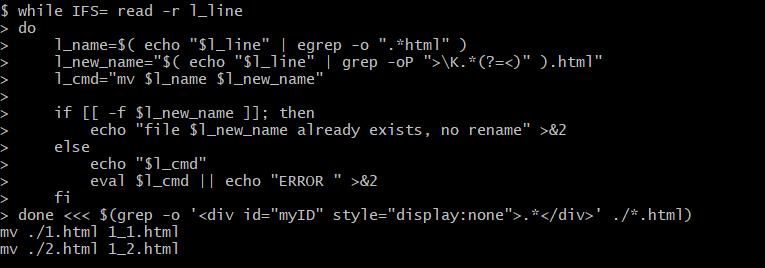
while IFS= read -r l_line
do
# get file name using exact match -o
l_name=$( echo "$l_line" | egrep -o ".*html" )
# get tag value using perl reg exp : values between >< ,
# \K (?=) remove brackets so without them we will get simple reg exp ">.*<"
# details https://unix.stackexchange.com/questions/13466/can-grep-output-only-specified-groupings-that-match
l_new_name="$( echo "$l_line" | grep -oP ">\K.*(?=<)" ).html"
# for echoing let use this variable
l_cmd="mv $l_name $l_new_name"
# rename if file does not exist
if [[ -f $l_new_name ]]; then
echo "file $l_new_name already exists, no rename" >&2
else
echo "$l_cmd"
# execute and inform if works
eval $l_cmd || echo "ERROR " >&2
fi
done <<< $(grep -o '<div id="myID" style="display:none">.*</div>' ./*.html)