Home > other > Big data real-time analysis architecture implementation?
Big data real-time analysis architecture implementation?
Time:09-20
CodePudding user response:
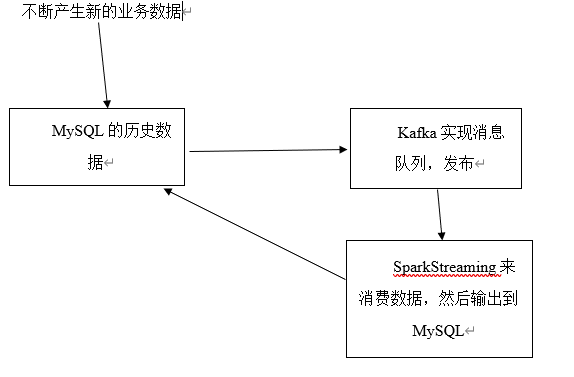
If Spark didn't to do data processing, why don't you directly MySQL master-slave synchronization, in statistical analysis from the library?
CodePudding user response:
1. The amount of data in the future will certainly be more and more big 2. The data processing, according to the business scenario, real-time measure of development will still use the spark, directly with mysql index development does not conform to the business development in the future