I have a excel (.xslx) file with 4 columns: pmid (int) gene (string) disease (string) label (string)
I attempt to load this directly into python with pandas.read_excel
df = pd.read_excel(path, parse_dates=False)
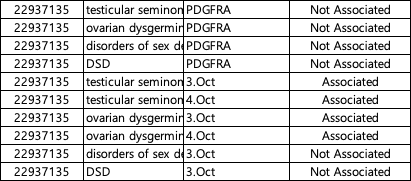
capture from excel
capture from pandas using my ide debugger
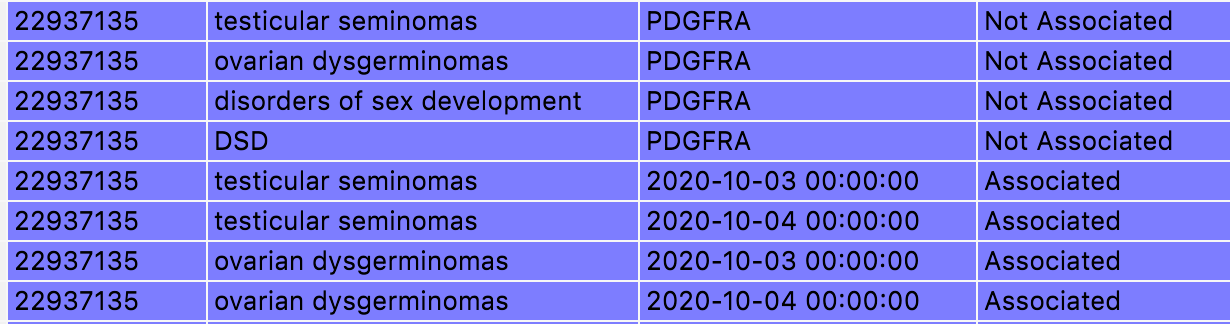
As shown above, pandas tries to be smart, automatically converting some of gene fields such as 3.Oct, 4.Oct to a datetime type. The issue is that 3.Oct or 4.Oct is a abbreviation of Gene type and totally different meaning. so I don't want pandas to do so. How can I prevent pandas from converting types automatically?
CodePudding user response:
pd.read_excel has a dtype argument you can use to specify data types explicitly.
CodePudding user response:
Force dtype=str to prevent Pandas try to transform your dataframe
df = pd.read_excel(path, dtype=str)
Or use converters={'colX': str, ...} to map the dtype for each columns.