I've got confused about how tasks are scheduled in a multi-core processor. Actually, different sources have different opinions. Importantly, there isn't enough document about tasks scheduling mechanism in a multi-core processor. Therefore, I decided to ask you a question.
I depicted a process that contains a process kernel thread, and two user-level threads. and provide a pseudo-code about the processing logic.
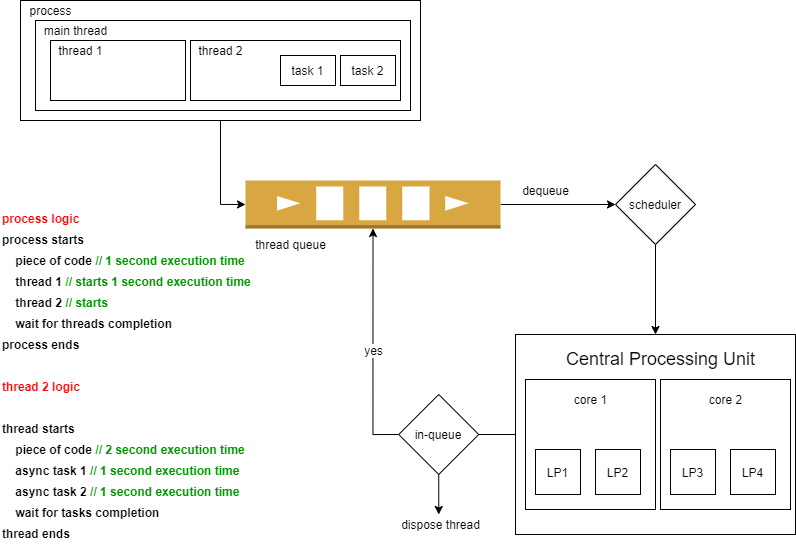
The question is, How this process will be executed in a multi-core processing unite that contains 2 physical cores and 4 logical processors (each core has 2). Such that, there are not any waiting processes, and the CPU was assigned to the process completely.
I guess it works like below:
Note: PKT_C1_LP1 means process kernel thread is assigned to core 1 and logical processor 1
|--PKT_C1_LP1--1s--| |--T1_C1_LP1--1s--| |--TSK1_C1_LP1--1s--|
|--T2_C1_LP2--2s-----------| |--TSK2_C1_LP2--1s--|
----------- timeline ----------->
Update
Seems like the answer(s) to your question(s) will depend a lot on what OS and scheduler your system is running.
Because there aren't any waiting processes and also enough resources. So I believe that almost all of the scheduling algorithms in any os will have insignificant differences. However, let's say, for simplicity it is:
non-preemptive FCFS scheduling
CodePudding user response:
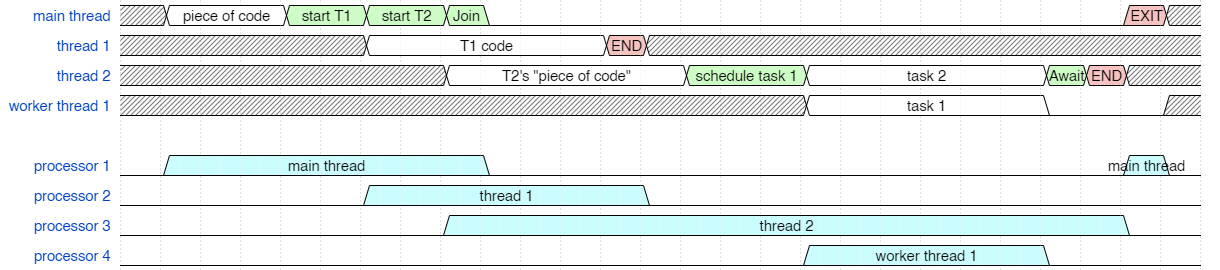
Here's a timing diagram of the code that each thread needs to execute. This imagines a maximal case where each task immmediately spawns a new thread. The green sections are infinitesimally short pieces of code (think, "not-to-scale") but are basically just scheduling operations. And the red sections are similarly short process EXIT and thread END scheduling operations. (I've omitted penalties associated with thread creation. And notice that worker threads do not END, they just go idle, and they stay in a thread pool.
Basic Timing Diagram

Now the first thing you'll notice is that, because of the way tasks work, the second task can be executed on the same thread that scheduled it, because no more tasks are scheduled, and the thread is only going to await that task. This has nothing to do with thread scheduling, and everything to do with how tasks efficiently manage their pool of worker threads. This is application-level code, not os-level code that accomplishes this. The diagram below requires 1 fewer threads thanks to tasks.
Timing Diagram with smarter tasks

Now we can look at what the scheduler needs to do. We are still dealing with only logical processors. (The details of which core will execute which thread are complicated so let's leave that out for the moment.) Here we see that we can naively execute all each of these threads on their own processor.
Greedy usage of processors
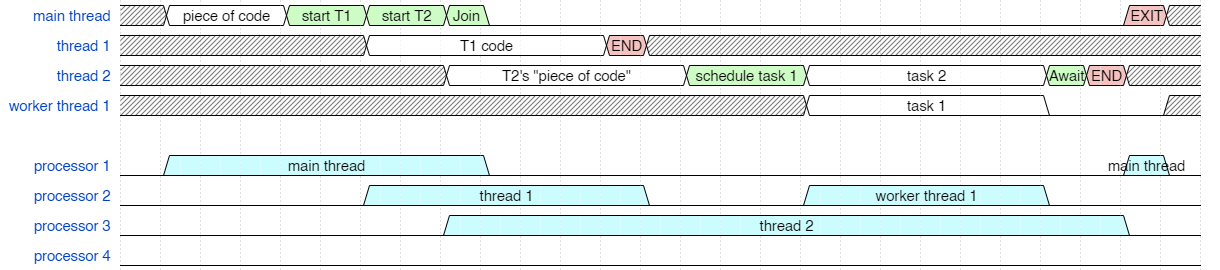
It will likely be more efficient to execute the worker thread on one of the previous processors. They are idle when worker thread 1 needs to execute, so it makes more sense to reuse one of the previously allocated processors. Here task 1 code in worker thread 1 is shown executing on processor 2 (could also have been assigned to processor 1 because it is also free, but stay tuned for the next diagram and you'll see why I put it on processor 2).
Schedule thread to reuse a processor
And finally, we can construct the last version that takes us to the most efficient scheduling. This hinges on optimizing the case where you create a thread and then immediately join a thread. Different operating systems try to optimize this case so that the newly created thread can run on the same processor. It means that creating the thread doesn't immediately schedule the new thread on a free processor and burn the cost of a context switch back to the thread that scheduled it. Instead, the new thread is scheduled when we block in our Join operation, or when the next clock interrupt occurs. If we can quickly get to our Join call before an interrupt triggers the scheduler (we're talking < 10 ms on a typical operating systems for such things to be triggered by the clock chip) then the scheduling will happen more efficiently like this (below), where thread 2 can be scheduled to run on the same processor without a context switch. (Interestingly, Linux and Windows optimize this case differently.)
Final timing diagram
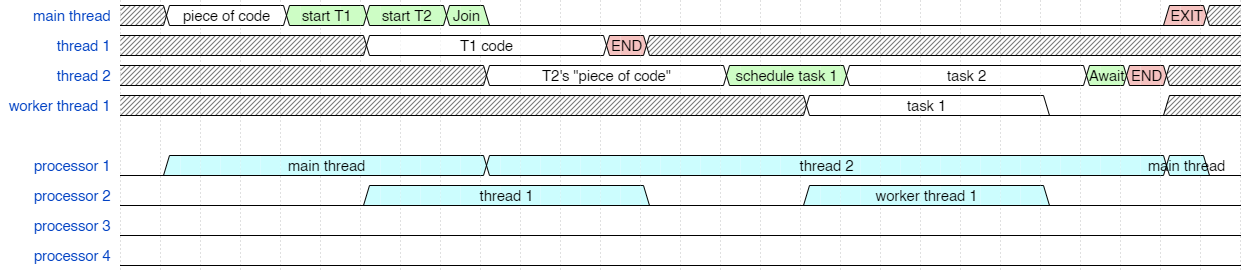
You'll notice (above) that this can now all execute on only two logical processors.
Whether it is more efficient to run these on separate cores or different logical processors of the same core is a nuance of the operating system again that depends highly on virtual memory usage and also the hardware specs of the processor and its caches. Different operating systems will do different things here, too. And the details matter greatly. Non-uniform memory architecture would affect the decision too.
In the real world, the operating system may use heuristics to determine the best priority and placement for threads and processes. The real world answer is so much different and more nuanced than this "computer science" answer I've given and depends on the specific details.
Additional Reading/Viewing: