I have the below pandas dataframe.
d = {'id1': ['85643', '85644','8564312','8564314','85645','8564316','85646','8564318','85647','85648','85649','85655'],'ID': ['G-00001', 'G-00001','G-00002','G-00002','G-00001','G-00002','G-00001','G-00002','G-00001','G-00001','G-00001','G-00001'],'col1': [1, 2,3,4,5,60,0,0,6,3,2,4],'Goal': [np.nan, 56,np.nan,89,73,np.nan ,np.nan ,np.nan, np.nan, np.nan, 34,np.nan ], 'col2': [3, 4,32,43,55,610,0,0,16,23,72,48],'col3': [1, 22,33,44,55,60,1,5,6,3,2,4],'Name': ['aasd', 'aasd','aabsd','aabsd','aasd','aabsd','aasd','aabsd','aasd','aasd','aasd','aasd'],'Date': ['2021-06-13', '2021-06-13','2021-06-13','2021-06-14','2021-06-15','2021-06-15','2021-06-13','2021-06-16','2021-06-13','2021-06-13','2021-06-13','2021-06-16']}
dff = pd.DataFrame(data=d)
dff
id1 ID col1 Goal col2 col3 Name Date
0 85643 G-00001 1 NaN 3 1 aasd 2021-06-13
1 85644 G-00001 2 56.0000 4 22 aasd 2021-06-13
2 8564312 G-00002 3 NaN 32 33 aabsd 2021-06-13
3 8564314 G-00002 4 89.0000 43 44 aabsd 2021-06-14
4 85645 G-00001 5 73.0000 55 55 aasd 2021-06-15
5 8564316 G-00002 60 NaN 610 60 aabsd 2021-06-15
6 85646 G-00001 0 NaN 0 1 aasd 2021-06-13
7 8564318 G-00002 0 NaN 0 5 aabsd 2021-06-16
8 85647 G-00001 6 NaN 16 6 aasd 2021-06-13
9 85648 G-00001 3 NaN 23 3 aasd 2021-06-13
10 85649 G-00001 2 34.0000 72 2 aasd 2021-06-13
11 85655 G-00001 4 NaN 48 4 aasd 2021-06-16
I want to summarize some of the columns and add them back to the same datframe based on some ids in the "id1" column. Also, I want to give a new name to the "ID" column when we add that row. for example, I have some "id1" column slices.
#Based on below "id1" column ids I want to summarize only "col1","col2","col3",and "Name" columns. #Then I want to add that row back to the same dataframe and give a new id for "ID" column.
b65 = ['85643','85645', '85655','85646']
b66 = ['85643','85645','85647','85648','85649','85644']
b67 = ['8564312','8564314','8564316','8564318']
# I want to aggregate sum for col1,col2 and If possible col3 with average. Otherwise it also with sum.
# So final dataframe look like below
id1 ID col1 Goal col2 col3 Name Date
0 85643 G-00001 1 NaN 3 1 aasd 2021-06-13
1 85644 G-00001 2 56.0000 4 22 aasd 2021-06-13
2 8564312 G-00002 3 NaN 32 33 aabsd 2021-06-13
3 8564314 G-00002 4 89.0000 43 44 aabsd 2021-06-14
4 85645 G-00001 5 73.0000 55 55 aasd 2021-06-15
5 8564316 G-00002 60 NaN 610 60 aabsd 2021-06-15
6 85646 G-00001 0 NaN 0 1 aasd 2021-06-13
7 8564318 G-00002 0 NaN 0 5 aabsd 2021-06-16
8 85647 G-00001 6 NaN 16 6 aasd 2021-06-13
9 85648 G-00001 3 NaN 23 3 aasd 2021-06-13
10 85649 G-00001 2 34.0000 72 2 aasd 2021-06-13
11 85655 G-00001 4 NaN 48 4 aasd 2021-06-16
12 b65 10 106 61 aasd
13 b66 17 169 67 aasd
14 b67 67 685 142 aabsd
#I was tried to do it in groupby and pandas pivot table and didn't get to work. Any suggestion would be appreciated.
Thanks in advance!
CodePudding user response:
you can do this:
all_lists = [b65,b66,b67]
for item in all_lists:
x = dff[dff.id1.isin(item)]
y = x.sum()
y.id1 = ''
y.ID= ''
y.Goal =''
y.Name=''
y.Date = ''
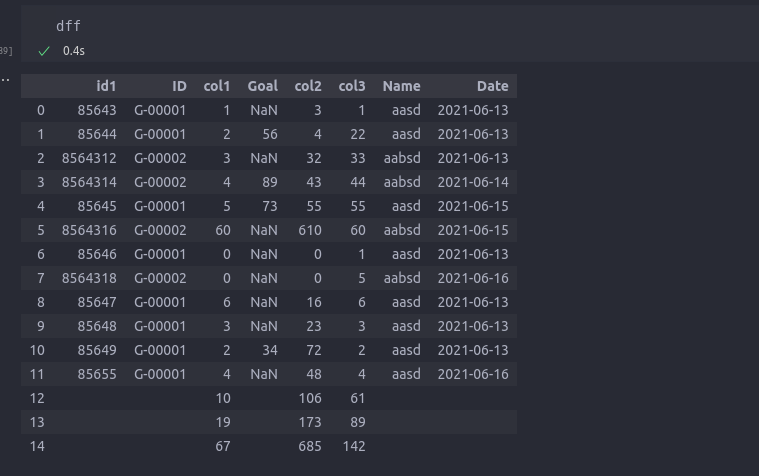
dff = dff.append(y,ignore_index=True)
and this is the result:
CodePudding user response:
I am not sure how you want to handle the name column but you could just add it to the agg function
b65 = ['85643','85645', '85655','85646']
b66 = ['85643','85645','85647','85648','85649','85644']
b67 = ['8564312','8564314','8564316','8564318']
# create a dictionary
d_map = {'b65': b65, 'b66': b66, 'b67': b67}
# dictionary comprehension
df = pd.DataFrame({k: dff[dff['id1'].isin(v)].agg({'col1': sum, 'col2': sum,
'col3': 'mean', 'Name': min})
for k,v in d_map.items()}).T.reset_index()
# rename the columns
df = df.rename(columns={'index': 'ID'})
# concat the two frames
pd.concat([dff, df]).reset_index(drop=True)
id1 ID col1 Goal col2 col3 Name Date
0 85643 G-00001 1 NaN 3 1 aasd 2021-06-13
1 85644 G-00001 2 56.0 4 22 aasd 2021-06-13
2 8564312 G-00002 3 NaN 32 33 aabsd 2021-06-13
3 8564314 G-00002 4 89.0 43 44 aabsd 2021-06-14
4 85645 G-00001 5 73.0 55 55 aasd 2021-06-15
5 8564316 G-00002 60 NaN 610 60 aabsd 2021-06-15
6 85646 G-00001 0 NaN 0 1 aasd 2021-06-13
7 8564318 G-00002 0 NaN 0 5 aabsd 2021-06-16
8 85647 G-00001 6 NaN 16 6 aasd 2021-06-13
9 85648 G-00001 3 NaN 23 3 aasd 2021-06-13
10 85649 G-00001 2 34.0 72 2 aasd 2021-06-13
11 85655 G-00001 4 NaN 48 4 aasd 2021-06-16
12 NaN b65 10 NaN 106 15.25 aasd NaN
13 NaN b66 19 NaN 173 14.833333 aasd NaN
14 NaN b67 67 NaN 685 35.5 aabsd NaN
This is where the magic happens:
df = pd.DataFrame({k: dff[dff['id1'].isin(v)].agg({'col1': sum, 'col2': sum,
'col3': 'mean', 'Name': min})
for k,v in d_map.items()}).T.reset_index()
dff[dff['id1'].isin(v)] is called boolean indexing which filters your frame where id1 is in v or the value for each key in the dict. The dictonary comprehension iterates through the d_map dictionary's key (k) and values (v)
.agg is a function used to aggregate data