I have a dataframe which have lists or values in their columns; something like the following:
df
A B C D
0 [] [3] ['ON'] 5
1 'a' ['a'] ['ON'] 5
2 5 [3] ['ON'] 5
3 [] [3] ['ON'] 5
...
I would like to replace all the values inside columns A, B, and C with empty lists. I tried using .assign(column_name='value') seperatly for the columns A, B, and C. I can set a value but I cannot set an empty list. I do not want to use .apply(lambda x: []), since it is rather slow.
Is there any other way?
Expected Outcome:
df
A B C D
0 [] [] [] 5
1 [] [] [] 5
2 [] [] [] 5
3 [] [] [] 5
...
what I basically need isa pandas function which can do: change everything in columns=['A','B','C'] to []
CodePudding user response:
You can use:
df['A'] = [[]]*len(df)
CodePudding user response:
Try setting the column with a list comprehension.
E.g.
empty_col = [[] for x in range(len(df))]
df['A'] = empty_col
df['B'] = empty_col
df['C'] = empty_col
>>> df
A B C D
0 [] [] [] 5
1 [] [] [] 5
2 [] [] [] 5
3 [] [] [] 5
...
CodePudding user response:
df['A'] = [np.empty(0,dtype=float)]*len(df)
df['B'] = [np.empty(0,dtype=float)]*len(df)
df['C'] = [np.empty(0,dtype=float)]*len(df)
Performance comparison:
for seed data:
df = pd.DataFrame(columns=['A'])
for i in range(100):
df = df.append({'A': i}, ignore_index=True)
df
With 1 000 elements: 396 µs vs 613 µs
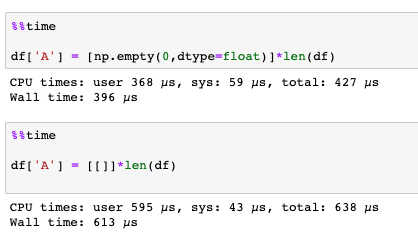
With 10 000 elements: 1.06 ms vs 4.33 ms
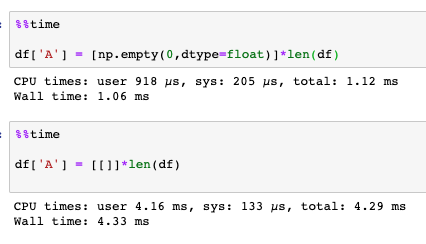
With 100 000 elements: 8.87 ms vs 45.9 ms
