There is an excel file which looks like the below image:
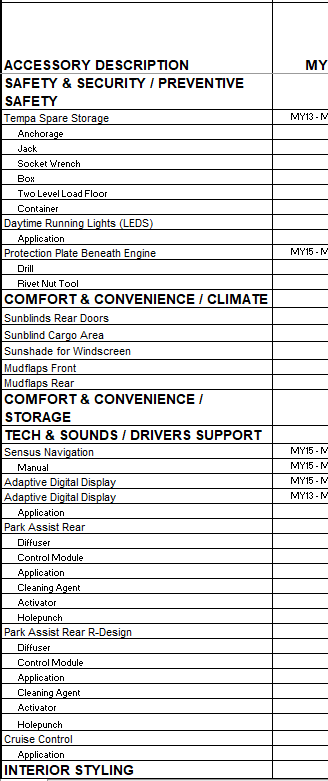
After using pd.read_excel() I have a dataframe that looks like so:
pd.DataFrame({'Accessory Description':['GROUP1','item1', 'item2','item3','item4','item5','GROUP2','item6','item7','item8'
,'item9','item10','GROUP3','item11','item12','item13','item14','item15']})
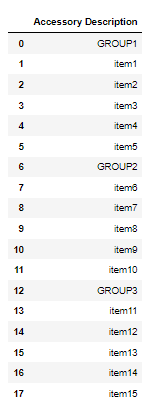
However I would like to manipulate the dataframe so that it is displayed as shown below:
pd.DataFrame({'Group':['Group1','Group1','Group1','Group1','Group1','Group2','Group2','Group2','Group2','Group2'
,'Group3','Group3','Group3','Group3','Group3']
,'Accessory Description':['item1', 'item2','item3','item4','item5','item6','item7','item8'
,'item9','item10','item11','item12','item13','item14','item15']})
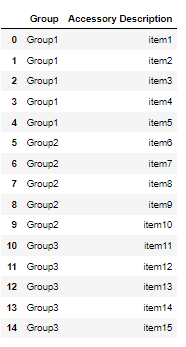
How do I go about doing this?
CodePudding user response:
Use Series.str.isupperwith Series.where and ffill for groups and then remove rows with same values in both columns:
s = df['Accessory Description'].where(df['Accessory Description'].str.isupper()).ffill()
df.insert(0, 'Group', s)
df = df[df['Group'].ne(df['Accessory Description'])].reset_index(drop=True)
print (df)
Group Accessory Description
0 GROUP1 item1
1 GROUP1 item2
2 GROUP1 item3
3 GROUP1 item4
4 GROUP1 item5
5 GROUP2 item6
6 GROUP2 item7
7 GROUP2 item8
8 GROUP2 item9
9 GROUP2 item10
10 GROUP3 item11
11 GROUP3 item12
12 GROUP3 item13
13 GROUP3 item14
14 GROUP3 item15