Having this dataframe:
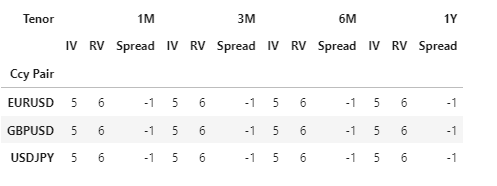
What's the best way to display as a dashtable ? I've tried manipulating the columns manually but didn't work
bottom_col_row = df2.columns.get_level_values(1) #------------
df2.columns = df2.columns.droplevel(1) #------------
columns=[{'name': [x[0], x[1]], 'id': x[0]} for x in zip(df2.columns, bottom_col_row)]
CodePudding user response:
Alright, this was a little tricky, but here's one way to get it to work in Dash's dash_table open-source table library:
import dash
import numpy as np
import pandas as pd
from dash import dash_table
# Create a pd.MultiIndex from the combination of t & m:
t = ["1M", "3M", "6M", "1Y"]
m = ["IV", "RV", "Spread"]
arrays = np.array(sorted([[b, a] for a in m for b in t]))
df = pd.DataFrame(
sorted(arrays, key=lambda x: (x[0][1], x[0][0])), columns=["Tenor", None]
)
index = pd.MultiIndex.from_frame(df)
# Create a mock df using random np floats, specifying the columns
# with the previously created pd.MultiIndex and the "index" here
# as the row labels
df2 = pd.DataFrame(
np.around(np.random.randn(3, 12), decimals=2),
index=["EURUSD", "GBPUSD", "USDJPY"],
columns=index,
)
# Dash app
app = dash.Dash(__name__)
"""For getting the columns fed correctly to dash_table,
a two-row multi-header can be created by suppling
the 'name' key of `DataTable.columns` with an array.
The trick then is to create unique IDs, which requires
manipulation of the data into a list of dictionaries
where each cell value's key is the artificially created
concatenated string (I just combined them; e.g., "1M_IV"
is one of the unique keys, and so on).
Note: the use of '**' is a useful Python3 way to merge
dicts during list/dict comprehensions. This is necessary
for including the true index 'Ccy Pair' as key,value
pairs in addition to a dict comprehension through the data.
Thus I needed to also transpose the df..."""
app.layout = dash_table.DataTable(
id="table",
columns=[{"name": ["Tenor", "Ccy Pair"], "id": "Ccy Pair"}]
[{"name": [x1, x2], "id": f"{x1}_{x2}"} for x1, x2 in df2.columns],
data=[
{
**{"Ccy Pair": df2.index[n]},
**{f"{x1}_{x2}": y for (x1, x2), y in data},
}
for (n, data) in [
*enumerate([list(x.items()) for x in df2.T.to_dict().values()])
]
],
merge_duplicate_headers=True,
# Optional interactivity parameters*:
editable=True,
filter_action="native",
sort_action="native",
sort_mode="multi",
column_selectable="single",
row_selectable="multi",
row_deletable=True,
selected_columns=[],
selected_rows=[],
page_action="native",
page_current= 0,
page_size= 10,
)
if __name__ == "__main__":
app.run_server(debug=True, dev_tools_hot_reload=True)
Which results in:
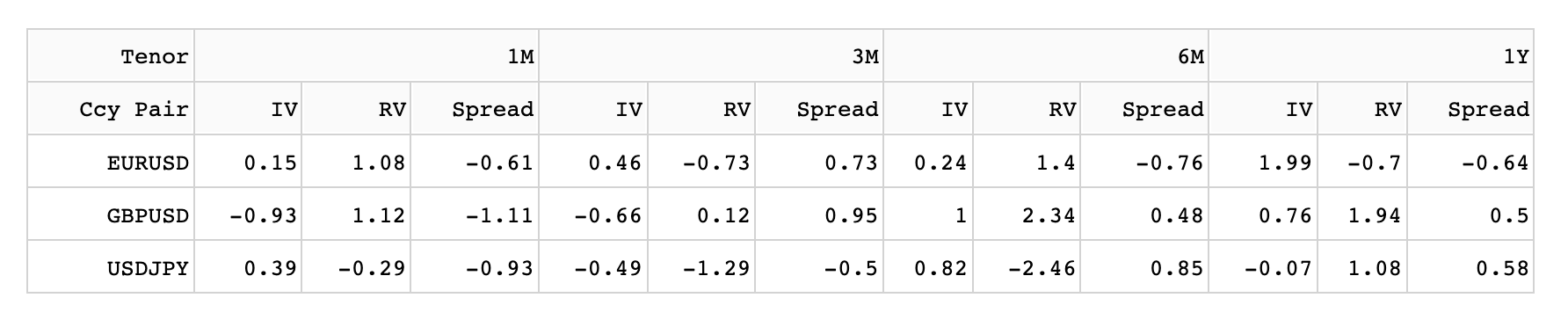
and with editing features added*:

Basically, this was the most helpful resource for me in figuring out how to manipulate the proper data structures: https://dash.plotly.com/datatable/style
Every cell has a [unique] column id which is f"{x1}_{x2}" where x1 ∈ ['1M', '3M', '6M', '1Y'] and x2 ∈ ['IV', 'RV', 'Spread']