I have the following dictionary
dict_map = {
'Anti' : {'Drug':('A','B','C')},
'Undef': {'Drug':'D','Name':'Type X'},
'Vit ' : {'Name': 'Vitamin C'},
'Placebo Effect' : {'Name':'Placebo', 'Batch':'XYZ'},
}
And the dataframe
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB04', 'AB05','AB06'],
'Drug': ["A","B","A",np.nan,"D","D"],
'Name': ['Placebo', 'Vitamin C', np.nan, 'Placebo', '', 'Type X'],
'Batch' : ['ABC',np.nan,np.nan,'XYZ',np.nan,np.nan],
}
I have to create a new column, which will used the data of the columns specified in the list to populate
cols_to_map = ["Drug", "Name", "Batch"]
The end result should look like this
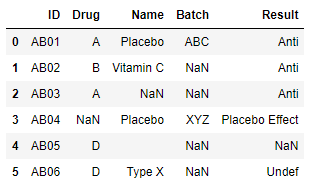
Note that 'Result' column has 'Anti' filled for first 3 rows despite having 'Vitamin C' and 'Placebo' is column 'Name' this is because 'Anti' comes first in dictionary. How do I achieve this using python? The dict_map can be restructured in anyway to meet this result. I'm not a python pro, I would really appreciate some help.
CodePudding user response:
First reshape nested dicts for separate values of tuples in nested dicts:
from collections import defaultdict
d = defaultdict(dict)
for k, v in dict_map.items():
for k1, v1 in v.items():
if isinstance(v1, tuple):
for x in v1:
d[k1][x] = k
else:
d[k1][v1] = k
print (d)
defaultdict(<class 'dict'>, {'Drug': {'A': 'Anti', 'B': 'Anti',
'C': 'Anti', 'D': 'Undef'},
'Name': {'Type X': 'Undef', 'Vitamin C': 'Vit ',
'Placebo': 'PPL'}})
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB04', 'AB05','AB06'],
'Drug': ["A","B","A",np.nan,
"D","D"],
'Name': ['Placebo', 'Vitamin C', np.nan, 'Placebo', '', 'Type X']
}
)
Then mapping by dictioanry, prioritized is by order of column in list cols_to_map:
cols_to_map = ["Drug", "Name"]
df['Result'] = np.nan
for col in cols_to_map:
df['Result'] = df['Result'].combine_first(df[col].map(d[col]))
print (df)
ID Drug Name Result
0 AB01 A Placebo Anti
1 AB02 B Vitamin C Anti
2 AB03 A NaN Anti
3 AB04 NaN Placebo PPL
4 AB05 D Undef
5 AB06 D Type X Undef
cols_to_map = [ "Name","Drug"]
df['Result'] = np.nan
for col in cols_to_map:
df['Result'] = df['Result'].combine_first(df[col].map(d[col]))
print (df)
ID Drug Name Result
0 AB01 A Placebo PPL
1 AB02 B Vitamin C Vit
2 AB03 A NaN Anti
3 AB04 NaN Placebo PPL
4 AB05 D Undef
5 AB06 D Type X Undef
EDIT:
df['Result1'] = df['Drug'].map(d['Drug'])
df['Result2'] = df['Name'].map(d['Name'])
print (df)
ID Drug Name Result1 Result2
0 AB01 A Placebo Anti PPL
1 AB02 B Vitamin C Anti Vit
2 AB03 A NaN Anti NaN
3 AB04 NaN Placebo NaN PPL
4 AB05 D Undef NaN
5 AB06 D Type X Undef Undef
CodePudding user response:
Since the relation between dict and the expected result is quite intricate, I would use a function to apply on your DataFrame. This saves us from manipulating the dictionary:
def get_result(row):
result = np.nan
for k,v in dict_map.items():
if row['Name'] in v.values():
result = k
if row['Name'] and type(row['Drug']) == str and 'Drug' in v.keys() and row['Drug'] in v['Drug']:
return k
return result
df['Result'] = df.apply(lambda row: get_result(row), axis=1)
print(df)
Output:
ID Drug Name Result
0 AB01 A Placebo Anti
1 AB02 B Vitamin C Anti
2 AB03 A NaN Anti
3 AB04 NaN Placebo PPL
4 AB05 D NaN
5 AB06 D Type X Undef