I have a task with working with hierarchical data, but the source data contains errors in the hierarchy, namely: some parent-child links are broken. I have an algorithm for reestablishing such connections, but I have not yet been able to implement it on my own. Example: Initial data is
------ ---- ---------- -------
| NAME | ID | PARENTID | LEVEL |
------ ---- ---------- -------
| A1 | 1 | 2 | 1 |
| B1 | 2 | 3 | 2 |
| C1 | 18 | 4 | 3 |
| C2 | 3 | 5 | 3 |
| D1 | 4 | NULL | 4 |
| D2 | 5 | NULL | 4 |
| D3 | 10 | 11 | 4 |
| E1 | 11 | NULL | 5 |
------ ---- ---------- -------
Schematically it looks like:
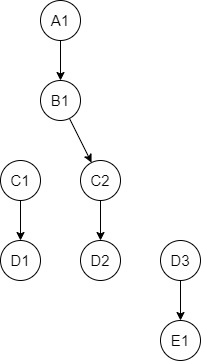
As you can see, connections with C1 and D3 are lost here. In order to restore connections, I need to apply the following algorithm for this table:
if for some NAME the ID is not in the PARENTID column (like ID = 18, 10), then create a row with a 'parent' with LEVEL = (current LEVEL - 1) and PARENTID = (current ID), and take ID and NAME such that the current ID < ID of the node from the LEVEL above.
Result must be like:
------ ---- ---------- -------
| NAME | ID | PARENTID | LEVEL |
------ ---- ---------- -------
| A1 | 1 | 2 | 1 |
| B1 | 2 | 3 | 2 |
| B1 | 2 | 18 | 2 |#
| C1 | 18 | 4 | 3 |
| C2 | 3 | 5 | 3 |
| C2 | 3 | 10 | 3 |#
| D1 | 4 | NULL | 4 |
| D2 | 5 | NULL | 4 |
| D3 | 10 | 11 | 4 |
| E1 | 11 | NULL | 5 |
------ ---- ---------- -------
Where rows with # - new rows created.And new schema looks like:
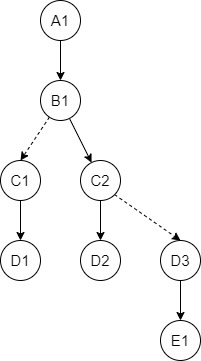
Are there any ideas on how to do this algorithm in spark/scala? Thanks!
CodePudding user response:
You can build a createdRows dataframe from your current dataframe that you union with your current dataframe to obtain your final dataframe.
You can build this createdRows dataframe in several step:
- The first step is to get the IDs (and LEVEL) that are not in PARENTID column. You can use a self left anti join to do that.
- Then, you rename
IDcolumn toPARENTIDand updatingLEVELcolumn, decreasing it by1. - Then, you take
IDandNAMEcolumns of new rows by joining it with your input dataframe on theLEVELcolumn - Finally, you apply your condition
ID<PARENTID
You end up with the following code, dataframe is the dataframe with your initial data:
import org.apache.spark.sql.functions.col
val createdRows = dataframe
// if for some NAME the ID is not in the PARENTID column (like ID = 18, 10)
.select("LEVEL", "ID")
.filter(col("LEVEL") > 1) // Remove root node from created rows
.join(dataframe.select("PARENTID"), col("PARENTID") === col("ID"), "left_anti")
// then create a row with a 'parent' with LEVEL = (current LEVEL - 1) and PARENTID = (current ID)
.withColumnRenamed("ID", "PARENTID")
.withColumn("LEVEL", col("LEVEL") - 1)
// and take ID and NAME
.join(dataframe.select("NAME", "ID", "LEVEL"), Seq("LEVEL"))
// such that the current ID < ID of the node from the LEVEL above.
.filter(col("ID") < col("PARENTID"))
val result = dataframe
.unionByName(createdRows)
.orderBy("NAME", "PARENTID") // Optional, if you want an ordered result
And in result dataframe you get:
---- --- -------- -----
|NAME|ID |PARENTID|LEVEL|
---- --- -------- -----
|A1 |1 |2 |1 |
|B1 |2 |3 |2 |
|B1 |2 |18 |2 |
|C1 |18 |4 |3 |
|C2 |3 |5 |3 |
|C2 |3 |10 |3 |
|D1 |4 |null |4 |
|D2 |5 |null |4 |
|D3 |10 |11 |4 |
|E1 |11 |null |5 |
---- --- -------- -----