We have a Spark Job (see the code):
package io.companyname.industry.streaming
import java.nio.file.{Files, Paths, StandardCopyOption}
import java.util.TimeZone
import io.companyname.core.utils.AppConfig._
import io.companyname.core.utils.CloudFiles
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.StreamingQuery
import org.apache.spark.sql.types._
import org.apache.spark.sql.{ColumnName, DataFrame, SparkSession}
import org.apache.spark.storage.StorageLevel
object KafkaDataGeneratorJob extends CloudFiles {
private val hdfsHost = System.getenv("HDFS_HOST")
private val hdfsPort = System.getenv("HDFS_PORT")
val hdfsLocation: String = s"$hdfsHost:$hdfsPort"//"hdfs-hadoop-hdfs-nn:9000" //"hdfs-hadoop-hdfs-nn:9000"
val digitalTwinId = "NP20100000"
val homeZeppelinPrefix = "/home/zeppelin/"
def readFromCSVFile(path: String, shortPath: String)(implicit spark: SparkSession): DataFrame = {
implicit val hadoopConf = spark.sparkContext.hadoopConfiguration
copy("file:///" path, "hdfs://" hdfsLocation homeZeppelinPrefix "/generator/" shortPath)
println(path)
val schema = StructType(
StructField("id", LongType, nullable = false) ::
StructField("Energy Data", StringType, nullable = false) ::
StructField("Distance", StringType, nullable = false) ::
StructField("Humidity", StringType, nullable = false) ::
StructField("Ambient Temperature", StringType, nullable = false) ::
StructField("Cold Water Temperature", StringType, nullable = false) ::
StructField("Vibration Value 1", StringType, nullable = false) ::
StructField("Vibration Value 2", StringType, nullable = false) ::
StructField("Handle Movement", StringType, nullable = false) ::
Nil)
spark.read
.format("csv")
//.option("inferSchema", "true") //is it working?
//.option("header", "true") //is it working?
.schema(schema)
.option("delimiter", ";")
.option("maxFilesPerTrigger", 1)
.csv("hdfs://" hdfsLocation homeZeppelinPrefix "/generator/" shortPath)
.persist(StorageLevel.MEMORY_ONLY_SER)
}
def generateStream(divider: Int)(implicit spark: SparkSession): DataFrame = {
val rate = spark.readStream
.format("rate")
.option("rowsPerSecond", 1)
.option("numPartitions", 10)
.load()
//.withWatermark("timestamp", "1 seconds")
// println("Rate schema:")
// println(rate.schema.fields.mkString)
//
// println("Rate plan:")
// println(rate.queryExecution.toString)
//Thread.sleep(1000000)
println("Preparing to load the csv file from resource kikai.csv")
val input = getClass.getResourceAsStream("kikai.csv")
println("Loaded file from resource kikai.csv")
println("Input stream from resource kikai.csv details: " input.toString)
println("Creating temp file")
val tmpPath = Files.createTempDirectory("csv")
println("Creating temp directory path details: " tmpPath.getFileName)
val pathCopiedFIle = Paths.get(tmpPath.toString, "kikai.csv")
println("Creating temp file path details: " pathCopiedFIle.getFileName)
Files.copy(input, pathCopiedFIle, StandardCopyOption.REPLACE_EXISTING)
println("Creating temp file succeed")
val cvsStream = readFromCSVFile(tmpPath.toString, "" pathCopiedFIle.getFileName)
//println("CSV schema:")
//println(cvsStream.schema.fields.mkString)
//
// println("Before join:")
// println(cvsStream.queryExecution.toString)
//val cvsStream2 = cvsStream.as("csv").join(rate.as("counter")).where("csv.id == mod(counter.value,10)").withWatermark("timestamp", "1 seconds")
val cvsStream2 = rate.as("counter").join(cvsStream.as("csv")).where("csv.id == mod(counter.value," divider ")").withWatermark("timestamp", "1 seconds")
println("CSV schema:")
println(cvsStream2.schema.fields.mkString)
cvsStream2
// println("After join:")
// println(cvsStream2.queryExecution.toString)
}
def streamMqttMessageForSpecificColumn(columnName: String, dataFrame: DataFrame, topicName: String): StreamingQuery = {
implicit val spark: SparkSession = SparkSession
.builder
//.master("local[1]")
.config(
new SparkConf().setIfMissing("spark.master", "local[*]")
.set("spark.default.parallelism", "1")
.set("spark.sql.shuffle.partitions", "1")
.set("spark.sql.streaming.metricsEnabled", "true")
.set("spark.sql.session.timeZone", "UTC")
.set("spark.eventLog.dir", "file:///tmp/spark-events")
).getOrCreate()
spark.conf.set("spark.sql.session.timeZone", "UTC")
TimeZone.setDefault(TimeZone.getTimeZone("UTC"))
Logger.getRootLogger.setLevel(Level.WARN)
dataFrame.select(
lit(topicName) as "key",
//Energy Data = 2021-10-13T11:27:32.222Z : NP20100000 : 0.00 246.47 0.00
concat(date_format(col("timestamp"),"yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"), lit(" : "), lit(digitalTwinId), lit(" : "), lit(new ColumnName(columnName))) as "value")
.writeStream
//.trigger(Trigger.ProcessingTime(10))
.format("kafka")
//.format("console")
//.option("truncate", "false")
.option("checkpointLocation", s"hdfs://$hdfsLocation/checkpoint/kafkaDataGenerator$columnName")
.option("kafka.bootstrap.servers", kafkaLocation)
.option("topic", "mqtt")
.queryName("kafkaDataGenerator" columnName)
.start()
}
def generateStream()(implicit spark: SparkSession) {
@transient lazy val LOG = Logger.getLogger(getClass.getName)
implicit val spark: SparkSession = SparkSession
.builder
.master("local[1]")
//.config(new SparkConf().setIfMissing("spark.master", "local[1]"))
.getOrCreate()
spark.conf.set("spark.sql.session.timeZone", "UTC")
TimeZone.setDefault(TimeZone.getTimeZone("UTC"))
Logger.getRootLogger.setLevel(Level.WARN)
val df = generateStream(10)
// println("CSV schema:")
// println(df.schema.fields.mkString)
streamMqttMessageForSpecificColumn("Energy Data", df, "ESP_02/Energy Data")
streamMqttMessageForSpecificColumn("Distance", df, "ESP_02/Distance")
streamMqttMessageForSpecificColumn("Humidity", df, "ESP_02/Humidity")
streamMqttMessageForSpecificColumn("Ambient Temperature", df,"ESP_02/Ambient Temperature")
streamMqttMessageForSpecificColumn("Cold Water Temperature", df,"ESP_02/Cold Water Temperature")
streamMqttMessageForSpecificColumn("Vibration Value 1", df,"ESP_02/Vibration Value 1")
streamMqttMessageForSpecificColumn("Vibration Value 2", df,"ESP_02/Vibration Value 2")
streamMqttMessageForSpecificColumn("Handle Movement", df,"ESP_01/Handle Movement")
// println("After start:")
// println(df.queryExecution.toString)
//
//spark.streams.awaitAnyTermination(3000000)
}
def main(args: Array[String]): Unit = {
@transient lazy val LOG = Logger.getLogger(getClass.getName)
implicit val spark: SparkSession = SparkSession
.builder
.master("local[1]")
//.config(new SparkConf().setIfMissing("spark.master", "local[1]"))
.getOrCreate()
spark.conf.set("spark.sql.session.timeZone", "UTC")
TimeZone.setDefault(TimeZone.getTimeZone("UTC"))
Logger.getRootLogger.setLevel(Level.WARN)
val df = generateStream(10)
// println("CSV schema:")
// println(df.schema.fields.mkString)
streamMqttMessageForSpecificColumn("Energy Data", df, "ESP_02/Energy Data")
streamMqttMessageForSpecificColumn("Distance", df, "ESP_02/Distance")
streamMqttMessageForSpecificColumn("Humidity", df, "ESP_02/Humidity")
streamMqttMessageForSpecificColumn("Ambient Temperature", df,"ESP_02/Ambient Temperature")
streamMqttMessageForSpecificColumn("Cold Water Temperature", df,"ESP_02/Cold Water Temperature")
streamMqttMessageForSpecificColumn("Vibration Value 1", df,"ESP_02/Vibration Value 1")
streamMqttMessageForSpecificColumn("Vibration Value 2", df,"ESP_02/Vibration Value 2")
streamMqttMessageForSpecificColumn("Handle Movement", df,"ESP_01/Handle Movement")
// println("After start:")
// println(df.queryExecution.toString)
//
spark.streams.awaitAnyTermination()
}
}
During the execution the Job fails each 13 seconds with OOM
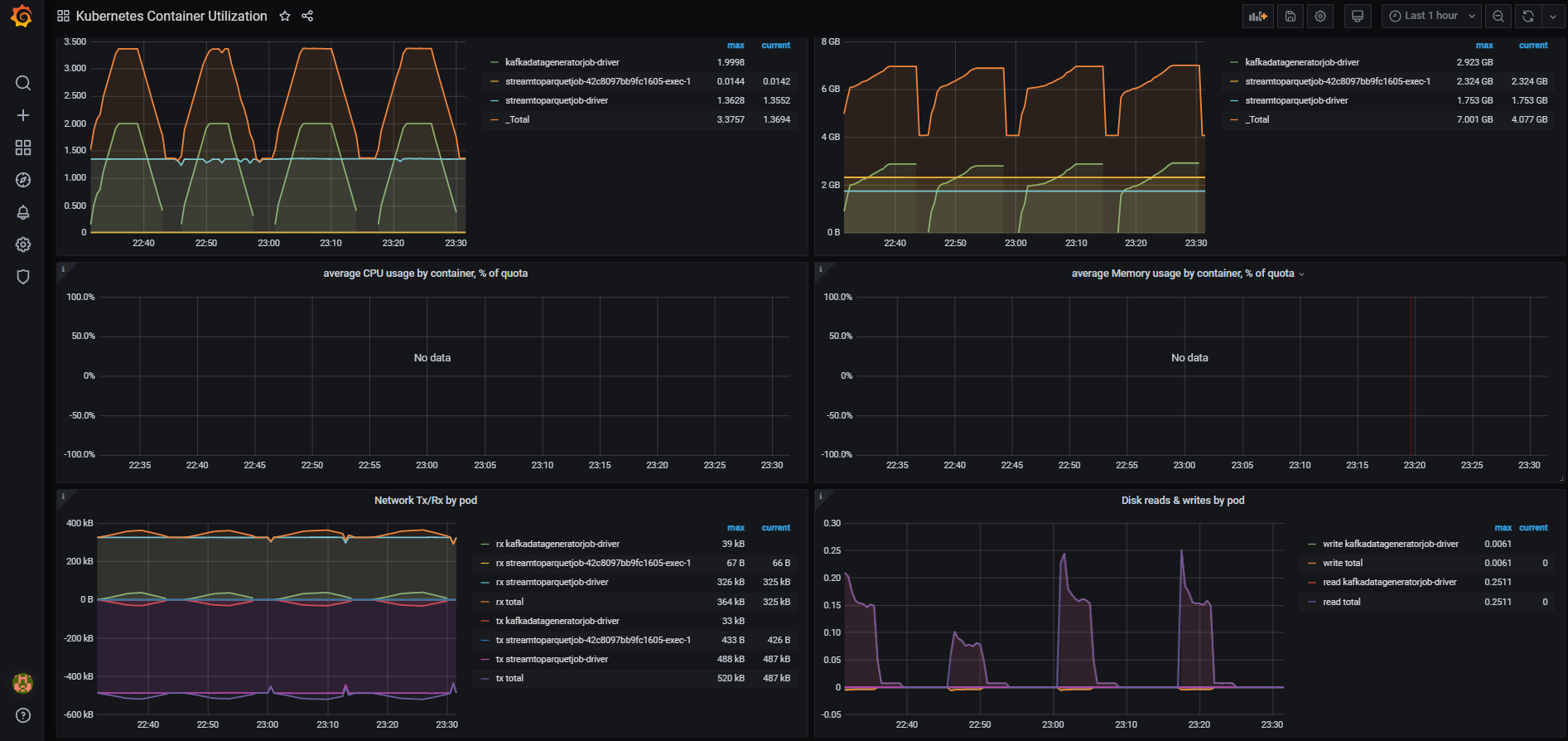
As for specific Spark metrics only looks increasing dramatically:
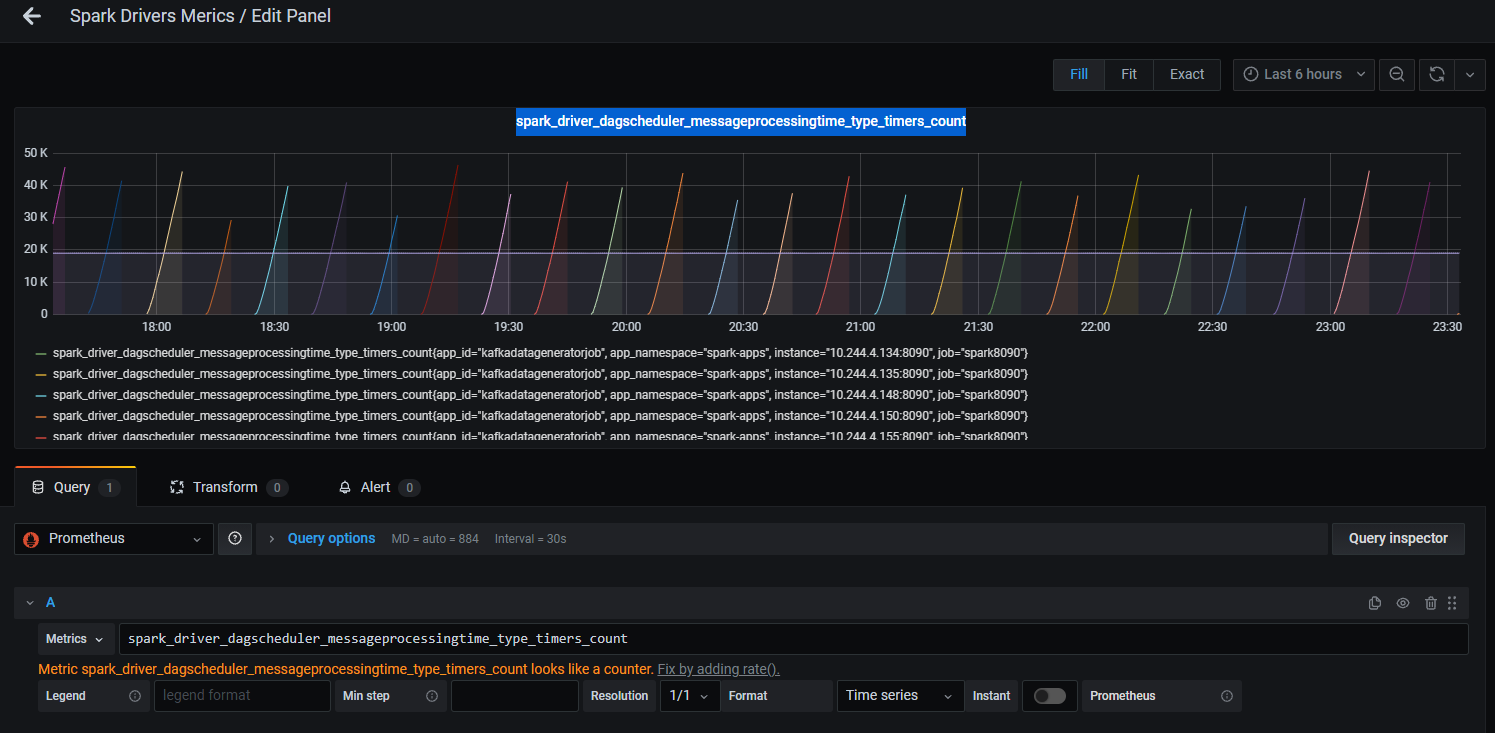
Is there any key for understanding what kind of leak I have here?
CodePudding user response:
From the PR that introduced this metric:
This commit adds a new metric, messageProcessingTime, to the DAGScheduler metrics source. This metrics tracks the time taken to process messages in the scheduler's event processing loop, which is a helpful debugging aid for diagnosing performance issues in the scheduler (such as SPARK-4961).