I was using a spark 1.6, yarn - client mode, through the spark thrift run the SQL server run batch,
Please the great god analysis analysis, in this thanked!


CodePudding user response:
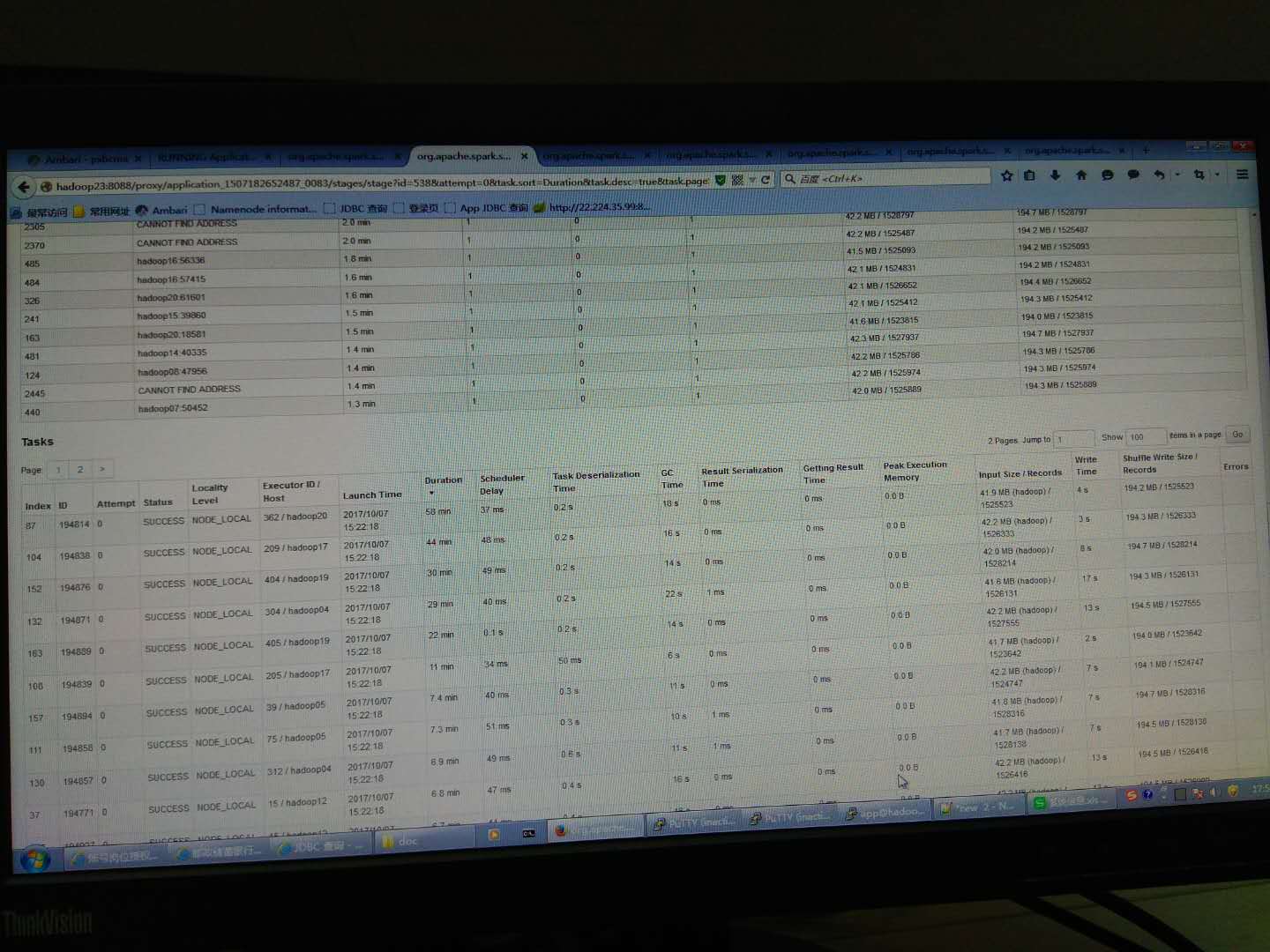
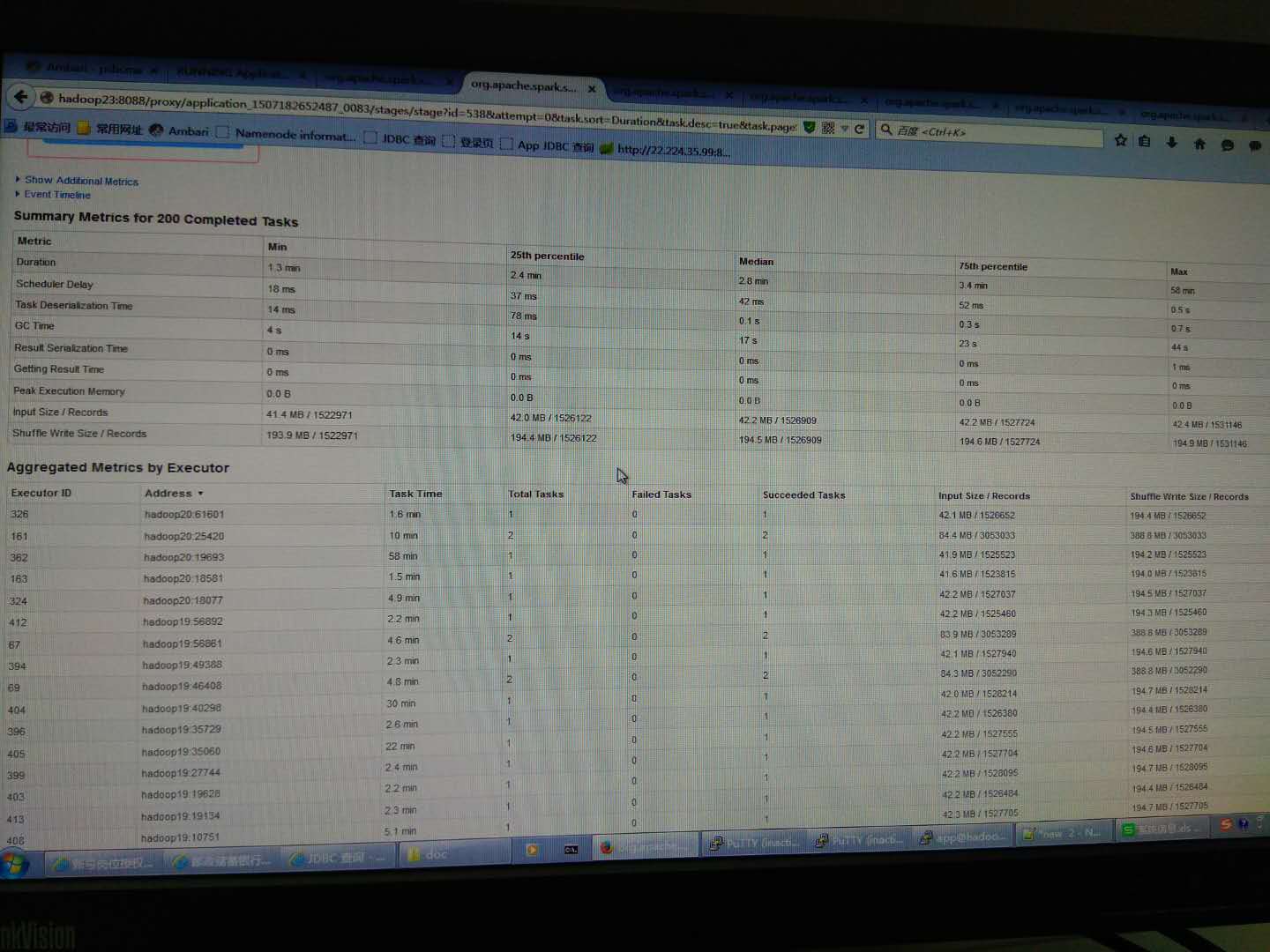
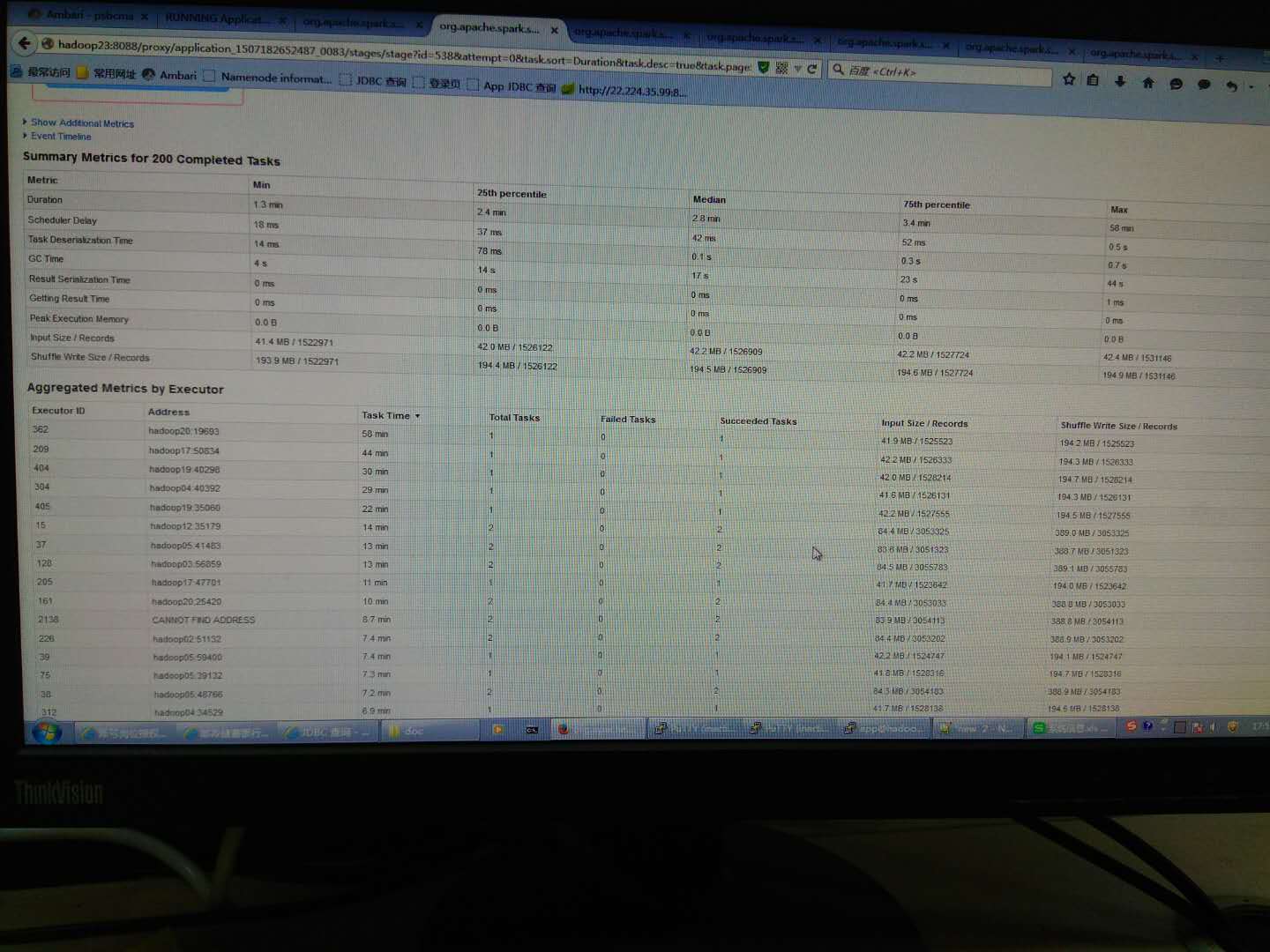
Look at the CPU utilizationJob, some special slow, check the CPU utilization is very low, we will try to reduce the number of each executor occupy CPU core, increasing the number of executor in parallel, and coupled with increasing fragmentation, overall increased CPU utilization, accelerate the speed of data processing,
Recommend an article, can consult, may help you
http://blog.csdn.net/kaaosidao/article/details/78174413
CodePudding user response:
Thank you, now is a executor4 cores, automatically assigned executor, partition is not set, then, will try a nuclear one executor, see if there is a changeCodePudding user response:
Into a executor after a nuclear, partition is not set, the situation is still the same, see below, most less than four minutes to complete, there is a 30 minute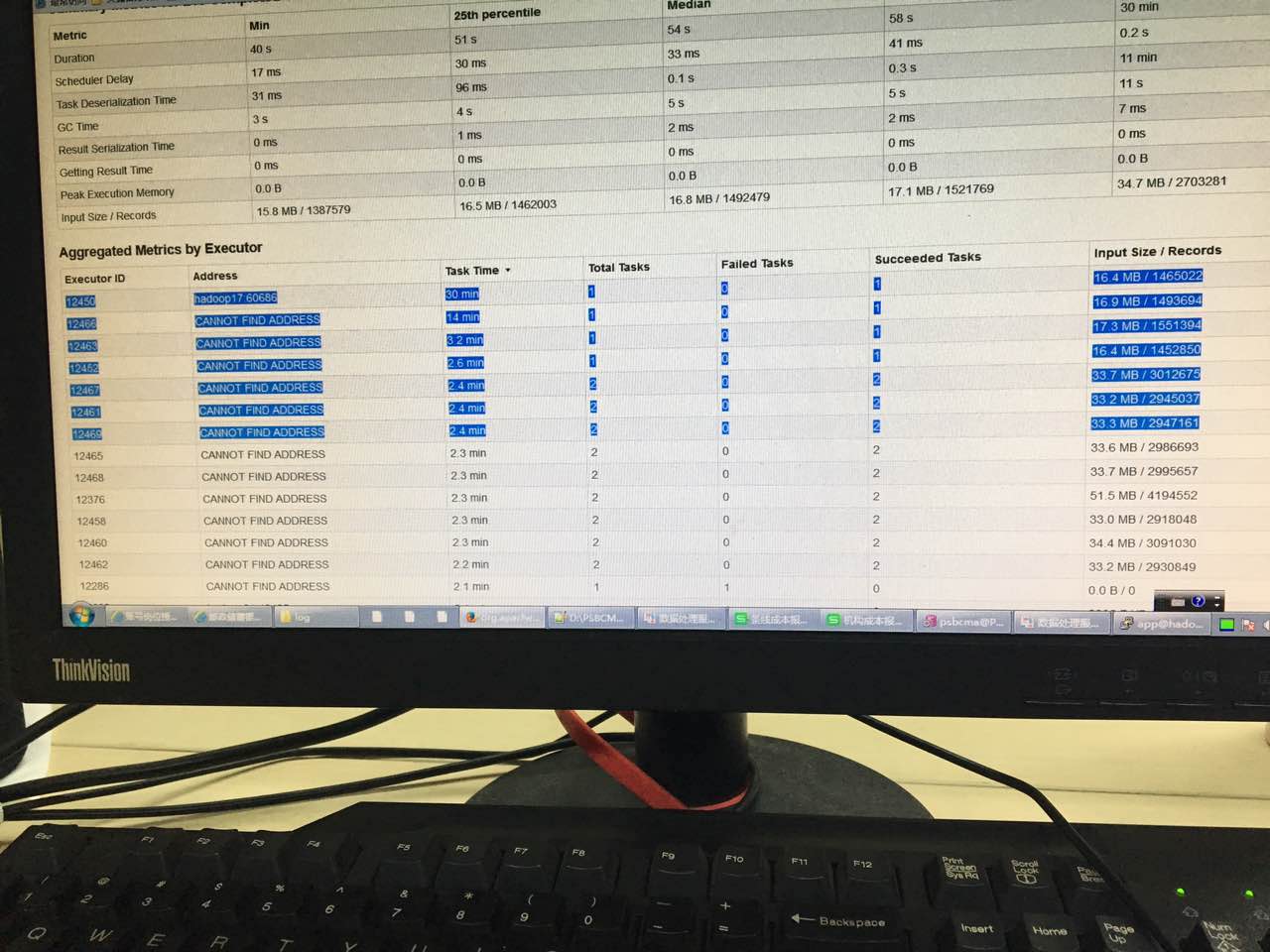
CodePudding user response:
To look on the slowest machine CPU is very free, very strange