I have dataframe i want remove star and all the empty line in localisation. I have to create two columns "temp" and "word". "temp" contains all the lines after the first line break and the column "word" represents all the words of this list [SECTION 11, CONE, BELLY, FIXED PLAN] found in "temp". My input :
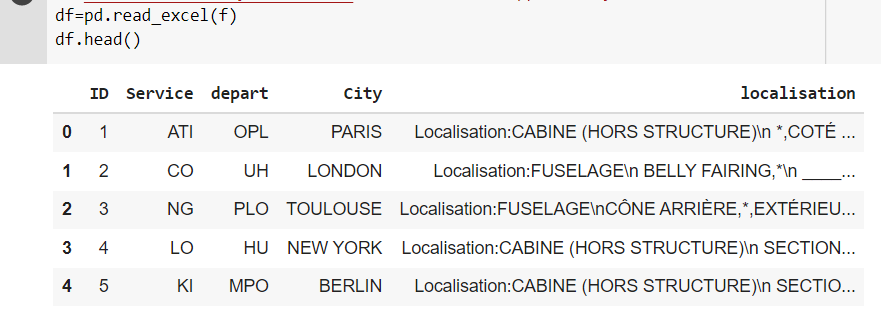
Ouput expected: I have to replace star with empty in the column word:

I try this but it doesn't work:
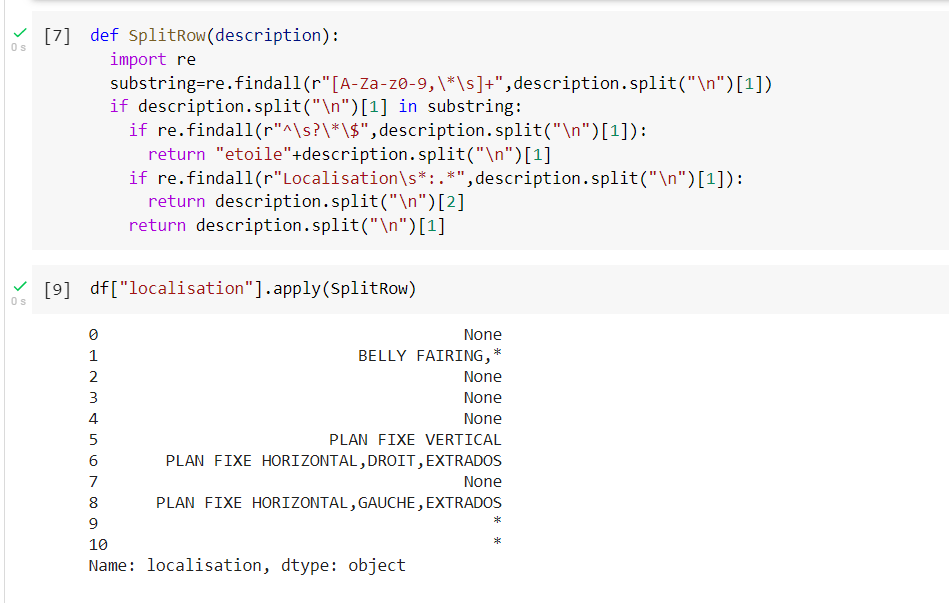
CodePudding user response:
You can use
import re
df['temp'] = df['localisation'].str.replace(r'^.*\n', '', regex=True)
words = ['SECTION 11', 'CONE', 'BELLY', 'FIXED PLAN']
df['word'] = df['temp'].str.findall(fr'(?<!\w)(?:{"|".join([re.escape(w) for w in words])})(?!\w)').str.join(', ')
Details:
.str.replace(r'^.*\n', '', regex=True)removes the first line with the line break.str.findall(fr'(?<!\w)(?:{"|".join([re.escape(w) for w in words])})(?!\w)')extracts all occurrences of thewordsas whole words (due to(?<!\w)and(?!\w)unambiguous word boundaries) in thetempcolumn while escaping all non-word chars in thewords..str.join(', ')at the end of the last code line is used to join the found list of matches with a comma space. You may further adjust what to join the matches with if you edit the argument in the.str.join()part.