My dataframe 1 looks like this:
| windcodes | name | yield | perp |
|---|---|---|---|
| 163197.SH | shangguo comp | 2.9248 | NO |
| 154563.SH | guosheng comp | 2.886 | Yes |
| 789645.IB | guoyou comp | 3.418 | NO |
My dataframe 2 looks like this
| windcodes | CALC |
|---|---|
| 1202203.IB | 2.5517 |
| 1202203.IB | 2.48457 |
| 1202203.IB | 2.62296 |
and I want my result dataframe 3 to have one more new column than dataframe 1 which is to use the value in column 'yield' in dataframe 1 subtract the value in column 'CALC' in dataframe 2: The result dataframe 3 should be looking like this
| windcodes | name | yield | perp | yield-CALC |
|---|---|---|---|---|
| 163197.SH | shangguo comp | 2.9248 | NO | 0.3731 |
| 154563.SH | guosheng comp | 2.886 | Yes | 0.40413 |
| 789645.IB | guoyou comp | 3.418 | NO | 0.79504 |
It would be really helpful if anyone can tell me how to do it in python.
CodePudding user response:
You can try something like this:
df1['yield-CALC'] = df1['yield'] - df2['yield']
I'm assuming you don't want to join the dataframes, since the windcodes are not the same.
CodePudding user response:
Do we need to join 2 dataframes from windcodes column? The windcodes are all the same in the sample data you have given in Dataframe2. Can you explain this?
If we are going to join from the windscode field. The code below will work.
df = pd.merge(left=df1, right=df2,how='inner',on='windcodes')
df['yield-CALC'] = df['yield']-df['CALC']
CodePudding user response:
I will try to keep it as elaborated as possible:
environment I have used for coding is Jupyter Notebook
importing our required pandas library
import pandas as pd
getting your first table data in form of lists of lists (you can also use csv,excel etc here)
data_1 = [["163197.SH","shangguo comp",2.9248,"NO"],\
["154563.SH","guosheng comp",2.886,"Yes"] , ["789645.IB","guoyou comp",3.418,"NO"]]
creating dataframe one :
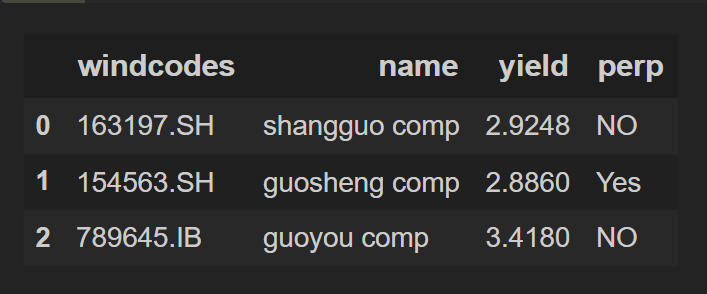
df_1 = pd.DataFrame(data_1 , columns = ["windcodes","name","yield","perp"])
df_1
Output:
getting your second table data in form of lists of lists (you can also use csv,excel etc here)
data_2 = [["1202203.IB",2.5517],["1202203.IB",2.48457],["1202203.IB",2.62296]]
creating dataframe two :
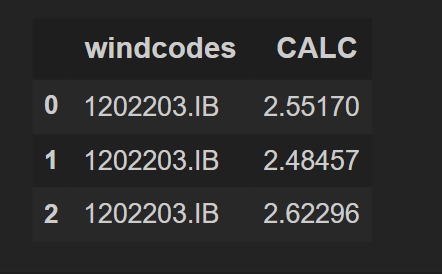
df_2 = pd.DataFrame(data_2 , columns = ["windcodes","CALC"])
df_2
Output:
Now creating the third dataframe:
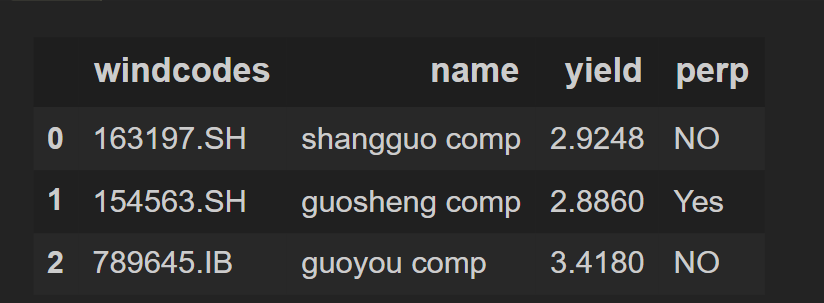
df_3 = df_1 # becasue first 4 columns are same as our first dataframe
df_3
Output:
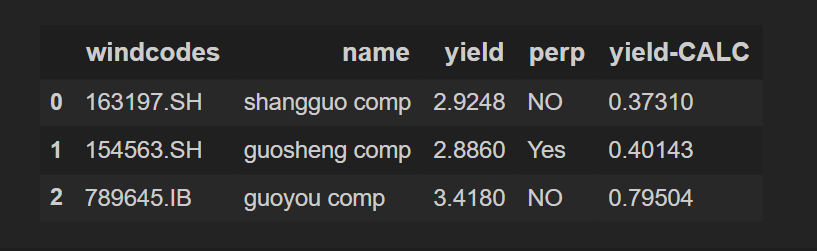
Now calculating the fourth column i.e "yield-CALC" :
df_3["yield-CALC"] = df_1["yield"] - df_2["CALC"] # each df_1 datapoint will be subtracted from df_2 datapoint one by one (still confused? search for "SIMD")
df_3
Output:
Hope you understood.
Happy coding!
CodePudding user response:
Just in case you have completely different indexes, use df2's underlying numpy array:
df1['yield-CALC'] = df1['yield'] - df2['yield'].values