The first part:
Why use Spark
HDInsight Linux introduction
Create a configuration Spark on HDInsight
The second part:
HDInsight monitoring and management of
Spark cluster using and application development and deployment
The third part
Using the Spark machine learning
Spark on a cluster of third-party applications
Spark profile
When it comes to big data analysis, we direct response is a Hadoop cluster, graphs, HDFS, etc, and related ecosystems, we are now talking about big data, however, is not just a huge amounts of data processing, including machine learning at the same time, flow analysis, data mining, graphic calculation... This is what the Spark as a big data processing based on distributed memory parallel framework one of the reasons for more and more fire, compared with traditional graphs, the Spark has the following advantages:
High performance: compared with traditional graphs, disk-based mode of operation, the Spark is a distributed computing framework based on memory, and because the RDD and the use of the Cache, data exchange based on memory, greatly enhance the performance, under different scenarios, 10 times to 100 times faster than graphs,
Easy to use: supports Java, Python, R, Scala development language, and Spark provide more than 80 kinds of abstract data conversion operations, let you can quickly build parallel processing procedure,
Ecosystem: the Spark has been built out of the perfect and mature ecosystems, built-in for HDFS, RDBMS, S3, Apache Hive, Cassandra and mongo, Azure Storage data sources, such as good support,
Unified engine: you can see from below, SQL, Spark Spark Streaming, Spark MLLib and Graphx were based on the core engine Spark, which means a platform can be unified in support of a variety of different applications, relative to the Hadoop fragmentation of the formation of ecological, much simpler for developers also efficient many
More scheduler support: although the Spark at the bottom of the data storage is still dependent on HDFS, however for resource scheduling, Spark can use YARN, can also use Mesos even separate scheduler, deployment is very flexible, especially in container technology is popular, you can run the Spark in the container, use Mesos to unified management
what is HDInsight
HDInsight is Microsoft launched cloud-based Hadoop big Data processing Platform, support the Storm, the Spark, HBase, R Server, Kafka, Interactive Hive (LLAP) and so on a variety of large Data framework, HDInsight Linux as the name suggests is at the bottom of the head node and Data nodes are based on Linux, is currently the Ubuntu 16.04 LTS, itself HDInsight is based on the Data of Hortonworks company, one of the big three Hortonworks Data Platform (HDP) to build, and according to the need of enterprise users in the cloud use, strengthen the safety management and the function of many sided,
If you are in your own data center before, in the cloud using HDInsight can bring many benefits for the enterprise, for example:
Easy to use, easy to deploy: for HDInsight cluster deployment, you don't need to understand the complex low-level details, head node, the node configuration data, different components, etc., in the Azure of the management interface, after a few simple clicks, a few minutes, a cluster of 16 node creates a success
According to pay: you don't need to run your business data, procurement of hardware, and the business machine when idle, wasting resources, you only need to calculate, create the cluster, can remove the cluster computing, Azure only billing according to usage, because of the separation of computing and storage properties, your database will be stored in the Azure storage, only need a small store of money every month
Elastic extension, you can according to you also no need, extend or extendable nodes on the interface number, can satisfy the demands of your business elastic
Rich services and version choice: HDInsight provide different versions of HBase, Hadoop, Spark, Storm, Hive, Pig, R, Kafka ecological system components and so on, and the automatic installation configuration, meet the demand of different business you
Open source 100% compatible: HDInsight HDP based building, and open source Hadoop fully compatible, which means that you have big data solutions, can quickly migrated to the cloud
End without or slight changes (such as data storage location) you can use the
Data persistence: can be seen from the following architecture, HDInsight HDFS based on Azure Storage implementation, means you store each score according to, will be the default Storage exactly the same, for the enterprise, the data security is the core, Azure Storage high availability, guarantee the reliability of data in any case
create HDInsight Linux for Spark
From the image below you can see, creating HDInsight simple steps, you can create a storage account first, used to store the Spark to deal with the data, can also create together when creating the cluster, then create a cluster, using Spark SQL for data processing, after the completion of the deployment in the way, you can use ARM template deployment, Powershell deployment or Linux/Mac using Azure CLI deployment, in this case, use the Azure management interface for deployment,
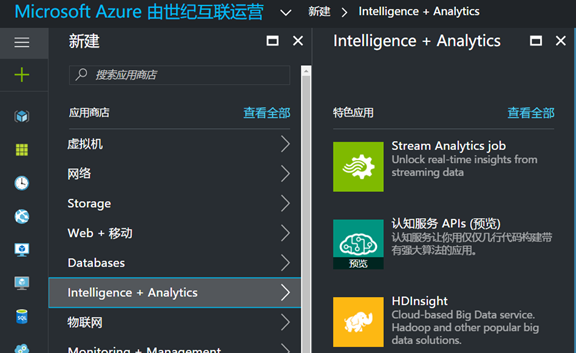
1. Open the new Azure portal, https://portal.azure.cn, select new, Intelligence + Analytics, you can see HDInsight icon, click on create:
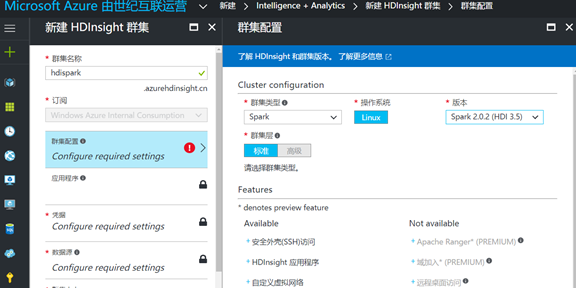
2. Give you a name of the cluster, in this case is called hdispark, configure the cluster, the cluster type, you can see we can choose the Hadoop, HBase, Storm, Spark, R server, and so on, we choose the Spark, only support Linux operating system currently types, choose Spark2.0 version, its corresponding HDP is version 3.5:
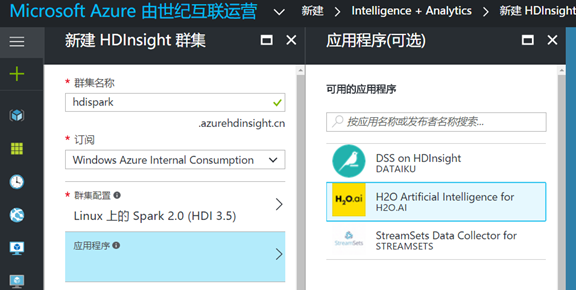
3. The application options section, you can see HDInsight Spark comes with some of the third party, based on the Spark set of tools and libraries, you can choose according to need to use, we'll ignore this part, in the next chapter in detail:
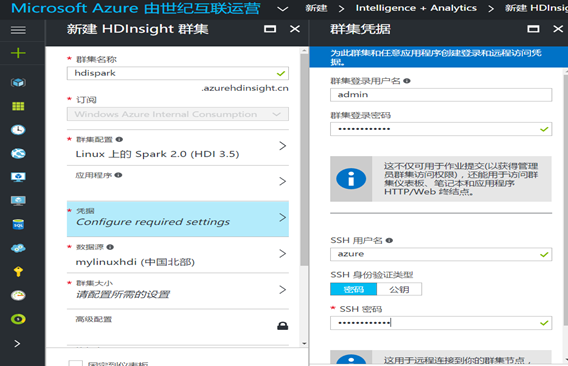
4. In the credential section, the first user name and password is behind you need to access the Ambari dashboards need user name password, the second user name password is you use SSH remote login user name password, set according to your habits, but the user name and password must remember, cannot recover after the peak season, behind will use to:
5. The part of Data source, where need to configure your Data storage, Data currently Lake China temporarily does not support, so we only use the Azure storage, configure your Data processing which is stored in the account, if it is created for the first time, you can choose to create new storage account, specify a name, or you can use you have to create storage account:
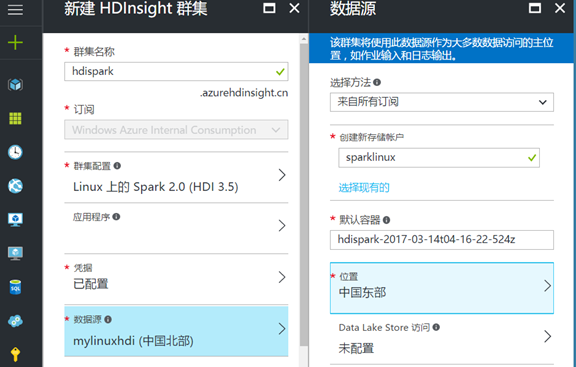
Note: if you want to delete the Spark computing cluster, still save the Hive and Oozie data, you need to create a SQL database is used to store data in advance:
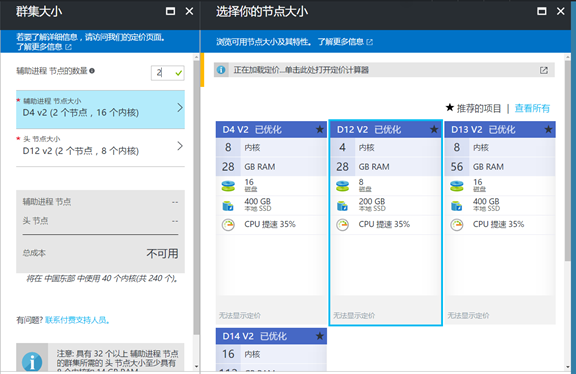
6. The Spark in the cluster, the default need two head node, you can specify multiple nodes, in cluster size, the need to select the appropriate node size, and the number of data nodes, the choice of this part is related to you how much the amount of data, how long does it take to complete, and relates to cost, need to do in advance planning, selection is finished, choose to determine:
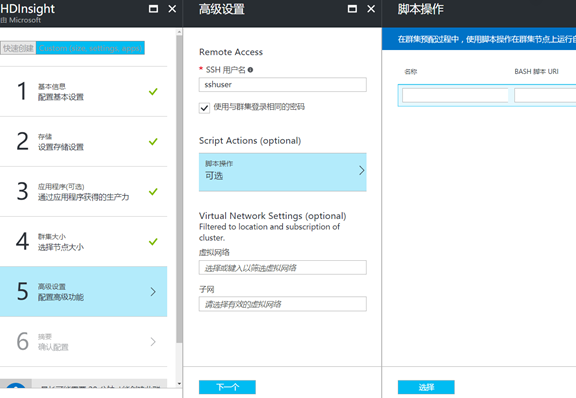
7. In the configuration of advanced features, you can choose to configure vNet, will Spark cluster to deploy your virtual network, so that the virtual network of the virtual machine can directly access the cluster; Can also custom scripts, after cluster deployment
Into extra again after deployment of new packages or perform the installation after operation; Click ok to create:
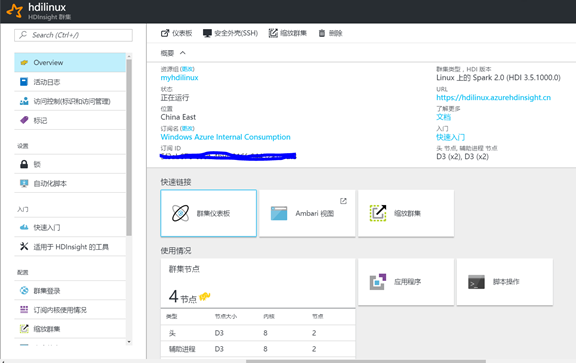
8. Create a complete, you can see the Spark of the cluster dashboard interface, you can see the dashboard interface, including cluster dashboard, Ambari, SSH login information, node information, in this case a total of four nodes, 2 head nodes, 2 working nodes:
Because of the space, we will in the next section, we introduce how to Spark cluster monitoring, management and application development and deployment of the Spark, interested friends, also can through the click here to know ,