I'm trying to make an normalise a co-occurrence matrix (I supposed it's called?) I have the following data sample coming in from a csv file:
import pandas as pd
df = pd.DataFrame({'A':[1,1,1,0,1,1,1,1],
'B':[1,0,1,0,1,1,1,1],
'C':[0,1,0,1,1,0,1,1],
'D':[1,1,1,1,0,1,1,1],
'E':[0,1,1,1,1,1,1,0]})
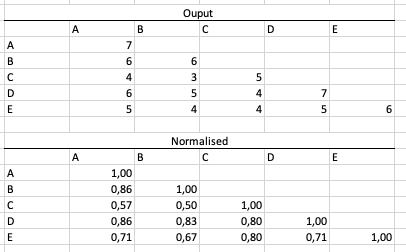
... and I have used the following approach to create this matrix:
(
CodePudding user response:
Use numpy:
import numpy as np
>>> coocc.divide(np.diag(coocc))
A B C D E
A 1.000000 1.000000 0.8 0.857143 0.833333
B 0.857143 1.000000 0.6 0.714286 0.666667
C 0.571429 0.500000 1.0 0.571429 0.666667
D 0.857143 0.833333 0.8 1.000000 0.833333
E 0.714286 0.666667 0.8 0.714286 1.000000
If you want to force the upper-diagonal values to zero, you can do:
>>> pd.DataFrame(np.tril(coocc.divide(np.diag(coocc))), columns=coocc.columns, index=coocc.index)
A B C D E
A 1.000000 0.000000 0.0 0.000000 0.0
B 0.857143 1.000000 0.0 0.000000 0.0
C 0.571429 0.500000 1.0 0.000000 0.0
D 0.857143 0.833333 0.8 1.000000 0.0
E 0.714286 0.666667 0.8 0.714286 1.0