I'm trying to scrape the news and signals tab from Crunchbase, and having no joy.
Having consulted prior threads on Stackoverflow, I have been using this code that has worked well for all other tabs (taking duolingo as an example):
website2 = "https://www.crunchbase.com/organization/duolingo/signals_and_news"
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept": "text/html,application/xhtml xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language": "en-US,en;q=0.5", "Accept-Encoding": "gzip, deflate", "DNT": "1", "Connection": "close", "Upgrade-Insecure-Requests": "1"}
response2 = requests.get(website2, headers=headers)
print(response2.content)
I suspect it's something to do with how Crunchbase has coded-up the news section, which probably requires a tweak to my header, but I'm not sure what I need do.
I'd be really grateful if anyone can help. Many thanks!
CodePudding user response:
Seems like news articles are generated dynamically in the backaground by javascript.
If you take a look at your web-inspector when loading your page you can see a request being made:
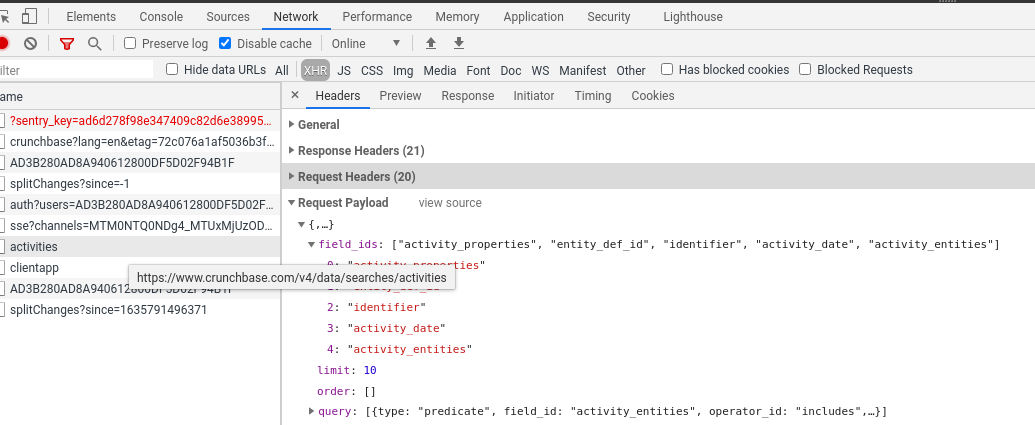
You can see it returns JSON data for news articles:
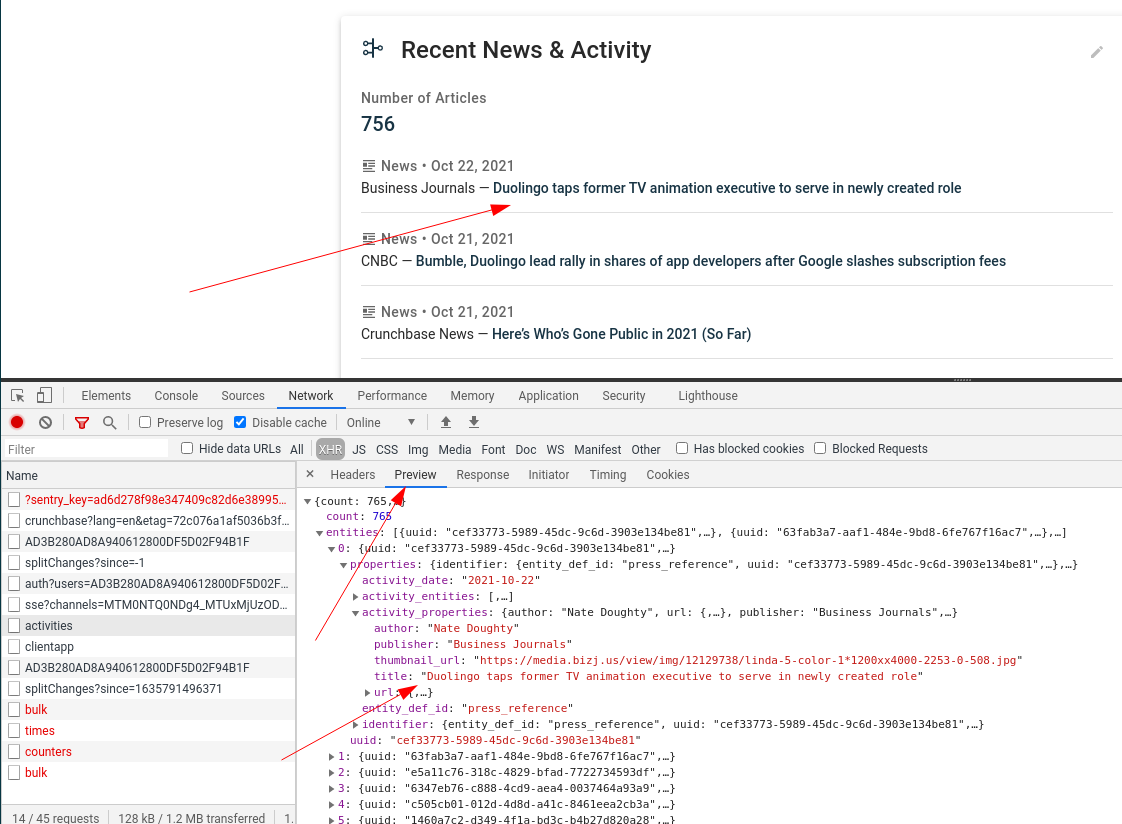
You have to replicate this request in your scraper code:
import requests
headers = {
'accept': 'application/json, text/plain, */*',
'x-requested-with': 'XMLHttpRequest',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) QtWebEngine/5.15.2 Chrome/87.0.4280.144 Safari/537.36',
'content-type': 'application/json',
'accept-language': 'en-US,en;q=0.9',
}
data = {'field_ids': ['activity_properties',
'entity_def_id',
'identifier',
'activity_date',
'activity_entities'],
'limit': 10,
'order': [],
'query': [{'field_id': 'activity_entities',
'operator_id': 'includes',
'type': 'predicate',
# this value is company page id, can be found in the html of original url
'values': ['c999a7f8-6a98-144a-e29f-05fb6df60f73']}]}
response = crequests.post('https://www.crunchbase.com/v4/data/searches/activities', headers=headers, data=data)
For more on reverse engineering websites with this method see my full blog post article here: https://scrapecrow.com/reverse-engineering-intro.html